
Deep explainer on large language models in crypto: how LLMs work, their role in research and trading agents, key infra and cost trends, and the security and governance risks shaping AI-native DeFi.
+10 sources across the wider coverage universe
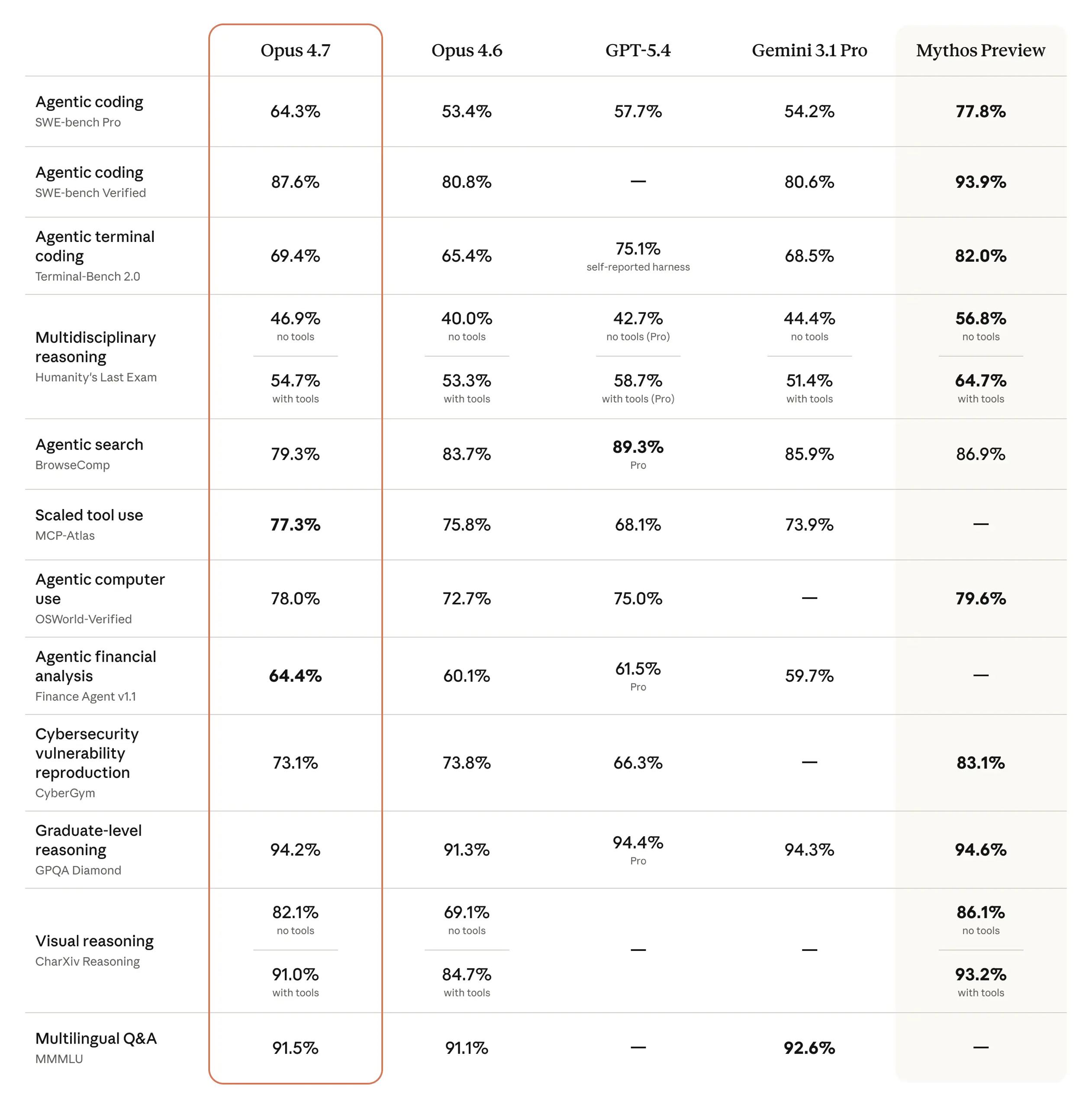 Anthropic ships Opus 4.7 with 3x coding gains and tripled image resolution, holding pricing steady2026-04
Anthropic ships Opus 4.7 with 3x coding gains and tripled image resolution, holding pricing steady2026-04 Firepan opens $239/mo DeFi vulnerability scanner for free as AI-powered exploits surge, urging developers to secure codebases before LLM-driven attacks escalate2026-04
Firepan opens $239/mo DeFi vulnerability scanner for free as AI-powered exploits surge, urging developers to secure codebases before LLM-driven attacks escalate2026-04 Researchers find 26 LLM API routers secretly injecting malicious code and stealing developer credentials2026-04
Researchers find 26 LLM API routers secretly injecting malicious code and stealing developer credentials2026-04 Vitalik Buterin unveils self-sovereign local LLM stack, prioritizing privacy, on-device inference, and secure data pipelines to eliminate reliance on centralized AI services2026-04
Vitalik Buterin unveils self-sovereign local LLM stack, prioritizing privacy, on-device inference, and secure data pipelines to eliminate reliance on centralized AI services2026-04 Google releases Gemma 4 open models with 256K context and multimodal support under Apache 2.0 license2026-04
Google releases Gemma 4 open models with 256K context and multimodal support under Apache 2.0 license2026-04 Google launches Gemma 4 12B encoder-free AI model, signaling a major shift in local LLM approach2026-06
Google launches Gemma 4 12B encoder-free AI model, signaling a major shift in local LLM approach2026-06
Large Language Models (LLMs) in Crypto and DeFi: An Evergreen Guide
As artificial intelligence systems trained on vast corpora of text to predict and generate language, large language models (LLMs) have become the core engine behind modern chatbots, coding assistants, and increasingly, autonomous agents in financial markets. In crypto and DeFi, these models are quietly moving from toy chat interfaces into the trading stack itself: powering research “digital twins,” routing orders through onchain execution layers, and even anchoring verifiable AI infrastructures that settle inference payments on-chain. This explainer lays out what LLMs actually are, how they work, why they matter for crypto, how they are being deployed as agents that hold wallets and trade across venues, which infrastructure layers and cost models underpin them, and what risks, governance questions, and long‑term design patterns are emerging as AI-native DeFi takes shape.
Understanding Large Language Models
Large language models are a class of artificial intelligence system designed to understand and generate human language by statistically modeling the structure of text. At their core, they are neural networks trained on massive datasets—ranging from books and web pages to code repositories and documentation—to predict the next token in a sequence, where a token is a small unit of text such as a word or subword. By repeatedly optimizing this next-token prediction task at scale, the model learns rich internal representations of syntax, semantics, and even world knowledge, which can then be harnessed for tasks like answering questions, summarizing documents, writing code, or reasoning through multi-step problems. The term “large” refers both to the size of the training corpus and to the number of model parameters, which for frontier systems reaches into the tens or hundreds of billions.
In practice, the behavior people associate with LLMs—conversational fluency, chain-of-thought reasoning, and the ability to follow instructions—arises from several stages of training layered atop this basic language modeling objective. After pretraining on raw text to learn general linguistic structures, models are usually “instruction-tuned” on curated datasets of prompts and responses so that they respond usefully to natural-language instructions. Many systems then undergo additional alignment steps, often using reinforcement learning from human feedback, to reduce harmful outputs and better match human preferences. The result is the now-familiar chat interface that can answer questions, write essays, debug code, or simulate a research analyst’s voice.
Although LLMs were initially deployed as general-purpose chatbots, their use has rapidly expanded into domain-specific workflows once they are combined with external tools and structured data. In industrial settings, they are increasingly embedded into “digital twin” systems that mirror complex physical or organizational processes and use LLMs for reasoning, orchestration, or natural language interfaces. For example, research has demonstrated LLM-enhanced enterprise digital twins in which the model assists with simulation, decision support, and updating the virtual representation of a firm’s operations. Similar ideas are being explored in domains like smart grids, where LLMs are used for forecasting, control support, and human-in-the-loop decision making across highly networked infrastructure. These real-world integrations foreshadow how LLMs can become reasoning and coordination layers for equally complex financial and blockchain-native systems.
From a crypto perspective, it is useful to distinguish between the LLM itself—the model weights and inference logic that turn tokens into tokens—and the wider system that surrounds it. The raw model is analogous to a virtual machine: powerful but context-agnostic. It only becomes a trading assistant, a governance delegate, or a DeFi risk manager once it is connected to data sources, tool APIs, and a set of policies or constraints that define what it is allowed to do. This is where the notion of agents enters: an LLM becomes an AI agent when it is embedded in an environment in which it can perceive, reason, and act over time, often via programmatic calls to external APIs such as exchanges, wallets, or onchain data services. Understanding this distinction—model versus agent—is essential for thinking clearly about LLMs in crypto.
How LLMs Work Under the Hood
Most state-of-the-art LLMs are built on the transformer architecture, which uses self-attention to let the model dynamically focus on different parts of the input sequence when predicting each token. During training, the model ingests batches of tokenized text and iteratively updates its parameters to minimize the difference between its predictions and the actual next tokens in the training data. This process, run across many GPUs or specialized accelerators, yields a set of weights that implicitly encode patterns in language and knowledge drawn from the corpus. Because the training objective is simple and generic, the same architecture can later be adapted to many tasks without changing the underlying model.
At inference time, when a user or an agent sends a prompt, the model converts the input into tokens, passes them through the network, and generates a probability distribution over possible next tokens. It then samples from that distribution according to a decoding strategy, which might favor the most likely token (greedy decoding) or introduce randomness to increase diversity (temperature sampling or nucleus sampling). These steps repeat until the model generates an end-of-sequence token or hits a length limit. The length of input plus output that a model can handle in a single pass is constrained by its context window; expanding this window has become a major area of development, especially for applications like portfolio research that involve long historical records, codebases, or onchain transaction histories.
The gap between raw language modeling and the structured, tool-using behavior needed for crypto and DeFi comes from system-level design rather than changing the core model. A typical agentic pipeline wraps the LLM in an orchestrator that handles tool selection, state management, and error correction. For example, an agent might respond to a user query by first calling a market data API, then summarizing the result, then generating an order, and finally passing that order to an execution system. Multi-agent frameworks push this further by spinning up specialized agents—such as a sentiment analyst, a technical strategist, and a risk manager—that communicate via natural language and coordinate on a final decision. This architecture closely mirrors how human trading firms organize expertise and is central to many of the LLM-in-crypto projects now launching on-chain.
Where LLMs Fit in the AI Landscape
LLMs are one pillar of modern AI, sitting alongside vision models, speech models, and reinforcement learning systems. What distinguishes LLMs is their flexibility: because so many tasks can be mapped into reading and writing text, a single model can assist with coding, research, translation, summarization, and conversational interfaces without task-specific retraining. This generality is amplified when models are extended to multimodal inputs and outputs, allowing them to process images, charts, or even audio alongside text. For crypto, this means a single LLM-based system can read whitepapers, parse Solidity code, inspect onchain events, and generate human-readable dashboards or governance summaries.
The line between narrow and general-purpose AI is also blurring as LLMs acquire stronger reasoning and planning capabilities. Recent research from Meta and Google has shown that automatically designing reasoning strategies—deciding when to think step-by-step, when to branch into multiple candidate chains of thought, and when to self-evaluate—can reduce the number of tokens needed for complex reasoning by nearly 70% while improving peak accuracy beyond hand-crafted baselines. Such advances are directly relevant to crypto use cases where long, complex analyses are expensive and time-sensitive, such as multi-venue arbitrage or protocol risk assessment. Meanwhile, companies like Anthropic report large gains in code quality and problem-solving on benchmarks like SWE-Bench with new frontier models like Claude Opus 4.7, which resolves roughly three times more production software tasks than its predecessor while holding pricing steady. These trends suggest that, for a given cost and latency budget, LLMs will continue to get better at the kind of structured reasoning and code manipulation that underpins sophisticated DeFi strategies.
Finally, the boundaries between centralized and decentralized AI infrastructure are becoming more fluid. Open-source models such as Google’s Gemma 4 12B, designed as encoder-free multimodal systems that can run on consumer laptops, illustrate a shift toward powerful local models that users can run privately. At the same time, decentralized GPU networks and verifiable inference protocols aim to provide scalable, trust-minimized access to larger models via APIs backed by crypto-economic guarantees. For crypto-native users, the choice is no longer just “which chatbot,” but “which model, running where, under which trust and cost assumptions”—a theme that recurs throughout this explainer.

Anthropic ships Opus 4.7 with 3x coding gains and tripled image resolution, holding pricing steady
^^
Crypto readers click LLM stories not for capability benchmarks but for infrastructure trust: the top-performing headlines all reduce to a single question — who controls the model stack, and what happens when that controller is malicious, centralized, or corruptible.↗
The 2026 LLM Landscape: Models, Costs, and Capabilities
The LLM ecosystem in the mid-2020s is characterized by three overlapping trends: frontier closed models accessible via cloud APIs; high-quality open models that can be self-hosted or run on decentralized infrastructure; and a burgeoning layer of cost-optimization and reasoning-efficiency research designed to make these systems economically viable at scale. Understanding this landscape helps crypto teams choose the right architectural patterns for their own AI agents and trading stacks.
Frontier models from labs such as Anthropic, OpenAI, and Google continue to push the envelope on raw capability and benchmark performance. Anthropic’s Claude Opus 4.7, for example, shows large improvements on software engineering tasks and long-context reasoning benchmarks, including resolving three times more real-world SWE-Bench tasks than the previous Opus release. Such models tend to be accessed via proprietary APIs, which offer strong performance and continuous upgrades but limit transparency and customizability. They are often the first to expose cutting-edge features like extended context windows, multimodal reasoning, and fine-grained tool use, making them attractive for early-stage experimentation with AI agents in trading, risk management, or DAO governance.
In parallel, the open-source ecosystem has matured rapidly. Google’s Gemma 4 12B is a notable example: a unified, encoder-free multimodal model explicitly designed for local, high-performance inference on consumer-grade hardware. By avoiding encoder–decoder splits and focusing on efficient architecture, Gemma 4 aims to bring advanced multimodal intelligence into settings where data privacy and low latency matter, such as local trading terminals or air-gapped research environments. Projects like this demonstrate that high-quality models no longer require a centralized API; they can be downloaded, fine-tuned, and integrated directly into crypto toolchains, including on nodes or infrastructure controlled by DAOs.
Cost and Efficiency: From Fine-Tuning Budgets to Agent Bills
Costs remain one of the most important constraints in LLM deployment, especially when models are embedded in always-on agents that make frequent calls to APIs. A detailed guide from io.net estimates that fine-tuning a large language model can cost anywhere from a few dollars to around three thousand dollars, depending on factors like model size, GPU tier, fine-tuning method (such as full fine-tuning versus low-rank adaptation), and training duration. Smaller models, or parameter-efficient methods such as LoRA adapters, can dramatically lower the barrier for teams that want to customize a model on their own research notes, trading logs, or codebases without incurring frontier-scale expenses.
Beyond training, inference and system-level costs add up quickly when agents operate at scale. TrueFoundry defines AI cost optimization as the practice of reducing and managing the total cost of operating AI systems, with a particular focus on inference compute, data movement, and ancillary infrastructure. Strategies include prompt engineering to reduce unnecessary tokens, caching and replay of common responses, model distillation and quantization to run cheaper variants, and routing logic that chooses among models based on task complexity. In crypto contexts, where an agent might poll multiple DEXs, compute complex analytics, and generate alerts for many users, these techniques are not merely nice-to-have—they can determine whether an AI-powered product is economically viable.
Research from Meta and Google suggests that smarter reasoning strategies can themselves be a powerful cost lever. By automating the selection of reasoning modes and using self-evaluation to prune unpromising chains of thought, their work reports reductions in reasoning token usage of up to 69.5%, while reaching better peak accuracy than any hand-designed baseline. This is particularly relevant for trading or risk analysis agents that tend to overuse verbose chain-of-thought prompting: with automated strategy selection, they can reserve intensive reasoning for genuinely hard problems and respond more succinctly elsewhere, directly lowering API bills.
At the infra level, new GPU architectures and specialized accelerators continue to push down the cost per token. While traditional cloud providers still dominate, crypto-linked infrastructure networks are emerging that pool GPU resources and expose them via token-incentivized marketplaces. Aethir, for example, operates a decentralized GPU cloud and has introduced Aethir Mesh as an API layer that lets developers access top-tier open-source LLMs through this distributed infrastructure. On top of that, Aethir Claw provides a managed environment for hosting AI agents on isolated VPS instances, bundling LLM API credits for frontier models and simplifying billing into a single subscription. This combination of decentralized compute and managed platform reflects a broader shift: instead of every team assembling a bespoke stack of VPS providers, LLM APIs, and key management, more integrated offerings are emerging that abstract away the complexity of agent deployment.
Local Models and Privacy-Preserving Design
One of the most important design choices for crypto users is whether to run models locally, via private infrastructure, or through third-party APIs. Local models such as Gemma 4 12B are explicitly positioning themselves for secure, offline, or latency-sensitive use cases. Because they run on hardware controlled by the user or organization, they can safely process sensitive data such as proprietary trading strategies, order-flow analytics, or private governance deliberations without exposing that information to external providers. For high-frequency or low-latency tasks, local deployment avoids the network round-trip and potential rate limits of cloud APIs.
However, local models are constrained by hardware capacity and may lag frontier APIs in raw capability, especially for complex reasoning or multimodal tasks. Hybrid approaches are therefore common: a local model handles routine queries and acts as a first-line assistant, while more demanding tasks are offloaded to frontier models via APIs, often through routing layers that centralize authentication and billing. In crypto, the privacy and censorship-resistance ethos often pushes teams toward maximal control, which can mean either self-hosted models or the use of privacy-preserving API routers.
Qtum.ai illustrates one version of this design. It offers a platform to privately build autonomous AI agents funded with crypto, with the Qtum Router acting as a drop-in replacement for OpenRouter so that developers can switch providers without rewriting their stack. This approach aims to allow experimentation with many major LLMs while keeping prompt data and financial operations under tighter control, and while leveraging crypto-native funding and accounting mechanisms. As agent fleets grow, such router layers can also be used to enforce risk limits, monitor usage, and direct traffic toward providers that satisfy regulatory or jurisdictional constraints.
Why LLMs Matter for Crypto and DeFi
Within crypto and DeFi, LLMs are migrating from being ad hoc research companions to becoming central components of trading systems, research organizations, and protocol operations. Their appeal stems from three overlapping capabilities: the ability to digest large volumes of unstructured information, the ability to interface with structured data and code, and the ability to act as programmable agents that execute workflows without constant human supervision. For an industry defined by information overload, complex technical stacks, and rapid market shifts, this combination is powerful.
One immediate application is research augmentation. Crypto investors must sift through whitepapers, GitHub repositories, governance forums, X and Telegram streams, onchain metrics, and traditional market data. LLMs excel at turning this heterogeneous, noisy input into structured summaries, risk checklists, and scenario analyses. They can, for example, read a protocol’s documentation, analyze its smart contracts, and generate a human-readable description of how funds flow through the system, including potential failure modes. They can monitor social media to track sentiment shifts and narrative formation, flagging when a token starts to attract outsized attention or coordinated campaigns. As some funds have already done, they can be wired into paper-trading pipelines that use LLM-derived sentiment or news embeddings as factors in multi-signal models, alongside more traditional metrics such as BTC dominance or exchange net flows.
From Chatbots to “Digital Twins” of Investors
A more ambitious pattern is emerging around digital twins—LLM-powered replicas of specific analysts, funds, or strategies built from historical artifacts. In enterprise settings, digital twin research integrates LLMs into simulations of organizations or physical systems, allowing models to reason over the digital representation and suggest optimizations or interventions. In the crypto research world, similar ideas are being applied to investors and analysts themselves. Serenity Twin, for example, is positioned as a “digital twin” of a well-known researcher’s investment thinking, trained on thousands of historical tweets, dozens of deep-dive reports, real-time market data, and strict logical constraints. Rather than being a generic chatbot, it aims to reproduce a particular person’s research style and mental models, enabling users to query “what would this analyst think about this token right now?” without manually combing through years of posts.
This digital twin approach addresses a problem that many crypto investors recognize: the “digital Sisyphus” of constantly reprocessing fragmented information flows without accumulating durable, structured insight. By encoding an analyst’s outputs and some approximation of their reasoning into an LLM-enhanced system, the twin can serve as a persistent, evolving representation of that research persona. It can be updated as new posts and research are published, and can be connected to live market feeds and onchain data. Over time, such twins could power everything from personalized newsletters to automated commentary on portfolio positions, or even act as governance delegates that vote according to the captured philosophy of a respected community member.
The same pattern could be applied to institutional investors, DAOs, or even individual traders. A fund might maintain an internal LLM twin trained on its investment memos, risk frameworks, and past decisions, which team members can query to ensure consistency with house style or to rapidly onboard new analysts. A DAO might encode its constitution, governance history, and risk parameters into an LLM system that answers member questions and drafts proposals aligned with prior practice. As digital twin research in other sectors shows, LLMs are well-suited to act as the reasoning layer inside such system-level twins, provided that their limitations and alignment issues are carefully managed.
Market Data, Onchain Analytics, and Execution Logic
LLMs also play a growing role in connecting the “narrative layer” of crypto—the stories and expectations that drive flows—with hard onchain and market data. They can summarize the impact of new regulatory announcements, parse protocol upgrade proposals, or explain the mechanics of new perp markets in plain language. When wired to onchain analytics platforms or custom queries, they can describe unusual activity, track wallet cohorts, and generate hypotheses about who might be accumulating or distributing a token. In many cases, their natural language output becomes a bridge between quantitative dashboards and human decision-makers.
Crucially, these models do not have to remain purely descriptive. When combined with tool access, they can translate their qualitative understanding into execution logic. A research agent might, after summarizing a token’s fundamentals and sentiment, propose a specific options structure to express a thesis, and then call into an execution agent that handles order placement and monitoring. A risk agent might continuously read protocol documentation and news to maintain an internal probability estimate of various risk scenarios, adjusting position limits or collateral preferences accordingly. As multi-agent LLM frameworks show, agents can negotiate, critique each other’s suggestions, and converge on a final policy in a way that loosely resembles human committees. For crypto teams, this means that LLMs can be embedded at every layer of the stack—from research, to portfolio construction, to trade execution, to risk supervision.

Firepan opens $239/mo DeFi vulnerability scanner for free as AI-powered exploits surge, urging developers to secure codebases before LLM-driven attacks escalate

Scanners commoditizing on both sides means defense-side LLM capability meets attack-side LLM capability at the same compile gate. Gervais's exploit-generation paper already showed AI agents finding novel reentrancy and price-manipulation bugs in unaudited contracts; the audit tier migrates up to adversarial state tracing and invariant fuzzing where cross-protocol composability still wrecks context windows. Nine-figure DeFi losses since 2022 mostly hit already-audited code. A free scanner raises the floor for solo devs shipping forks; the tail risk is where the money actually leaks.
- 01Sovereign on-device inference
Vitalik framing local LLM inference as a self-custody problem — eliminating dependence on closed API providers the same way non-custodial wallets eliminate exchange counterparty risk — translated AI privacy into crypto-native terms readers already accept.
- 02Malicious LLM router supply chain↗
26 production API routers secretly injecting code and stealing credentials showed that the middleware layer between developers and models is an active attack surface, not a passive pipe.
- 03AI-powered DeFi exploit escalation
Firepan opening its scanner free specifically because LLM-driven attacks were surging signaled to readers that AI is already being operationalized against smart contracts, not merely theorized.
- 04Open-weight model capability convergence↗
Google releasing Gemma 4 with 256K context and multimodal support under Apache 2.0 reinforced the thesis that frontier capability is migrating off closed API providers and onto self-hostable infrastructure.
- 05Frontier model pricing pressure↗
Anthropic holding Opus 4.7 pricing flat despite 3x coding gains set a concrete benchmark that developers use to evaluate whether closed API centralization is still economically justified.
Agentic LLM Systems on Crypto Rails
The concept of an AI agent is central to understanding how LLMs intersect with crypto infrastructure. An agent, in this context, is an LLM-based system equipped with tools and an environment, capable of perceiving inputs, planning actions, and executing those actions autonomously or semi-autonomously over time. In contrast to a simple question-answering model, an agent maintains state, uses APIs, and can trigger real-world effects such as placing trades or signing onchain transactions.
Multi-agent architectures extend this idea by deploying teams of specialized agents that interact with each other. TradingAgents, for instance, is an open-source framework that mirrors the dynamics of a real-world trading firm by assigning different roles to different LLM-powered agents, including fundamental analysts, sentiment experts, technical analysts, traders, and risk managers. These agents collaboratively evaluate market conditions, debate strategies, and produce actionable trading decisions, with the framework orchestrating their communication and enacting their final plan. This approach highlights a key advantage of LLMs: because they communicate naturally in language, orchestrating multi-agent discussion and delegation becomes conceptually similar to organizing a human team.
Research such as SiriuS proposes methods for self-improving multi-agent systems that learn from successful interactions and refine their collaboration strategies over time. SiriuS evaluates the trajectories produced by each agent team using a payoff function, retains high-reward trajectories, and augments low-performing ones with feedback before using them to fine-tune the agents via supervised learning. Experiments show that such systems can significantly improve performance on complex reasoning, biomedical QA, and negotiation tasks without explicit step-by-step supervision. For crypto, this suggests a future in which agentic trading or risk systems continually improve by training on their own historical playbook, including both profitable strategies and failure cases.
Onchain Trading Agents and EconomyOS
Bridging these agentic architectures to crypto markets requires secure, programmable interfaces between LLMs and onchain or exchange infrastructure. Virtuals EconomyOS is an example of this bridge in action, offering a platform where any LLM—from Claude or ChatGPT to code-centric tools like Codex or Cursor—can be connected to autonomous trading agents operating across crypto, equities, FX, and commodities via a single interface. Within the Virtuals ecosystem, LLM-powered agents can hold wallets, execute trades on venues such as Hyperliquid perps, settle payments, and coordinate with other agents, all governed by onchain protocols and standards like HIP-3 markets.
From the LLM’s perspective, EconomyOS provides a structured set of tools and affordances: functions to query balances, pull orderbook data, place and cancel orders, or transfer funds. The LLM agent receives observations about the environment, reasons about them using chain-of-thought or learned strategies, and returns actions encoded in a machine-readable format that the OS enforces. Risk limits, whitelists of allowed instruments, and circuit breakers can be implemented at the OS layer so that even if an agent’s reasoning goes awry, its ability to inflict damage is constrained. This pattern—LLM as high-level planner, OS as low-level executor—mirrors the separation between smart contract logic and transaction relayers in DeFi, and will likely become a design standard for safe AI agents in finance.
New token standards such as ERC-8126, which aims to represent AI agent fleets and their rights on-chain, fit into this picture by providing a canonical way to register, permission, and audit agent identities and behaviors at the protocol level. While details are still evolving, the general idea is to move from opaque, offchain bots to first-class onchain entities whose actions and constraints can be inspected, governed, and, if necessary, revoked. For traders and protocols, this opens the possibility of whitelisting or rate-limiting specific classes of agents, pricing access to liquidity based on observed behavior, or delegating governance votes to auditable AI delegates that represent known policies rather than anonymous scripts.
Private Autonomous Agents and Router Layers
Not all agent deployments will be fully on-chain. Many will be hybrid, combining offchain reasoning with onchain execution. Qtum’s initiative around Qtum.ai captures this pattern, emphasizing the ability to privately build autonomous AI agents funded with crypto, while using the Qtum Router as a drop-in replacement for OpenRouter so developers can switch providers without rewriting their stacks. In this architecture, the agent’s cognition—its prompts, internal memory, and strategy code—runs on infrastructure controlled by the user or trusted providers, while the router abstracts away the complexity of managing API keys and billing across many LLM vendors. Crypto is used as the funding and settlement layer for both inference costs and onchain operations.
Such router layers are particularly relevant for fleets of agents. A trading desk might operate dozens of agents tuned to different markets, horizons, and risk profiles. A protocol might spin up separate agents for customer support, documentation, security monitoring, and governance summarization. Managing the compute costs, permissions, and model selection for all of them quickly becomes non-trivial. By centralizing these concerns, routers and agent orchestration platforms allow teams to focus on specifying desired behavior and risk limits, rather than on the low-level plumbing of LLM access.
Research Foundations: Agentic LLM Decision-Making and Blockchain Optimization
Academic and industrial research is beginning to formalize the connection between LLM agents and blockchain systems. Through a collaboration with Peking University, Theta Network and its EdgeCloud initiative have announced two papers accepted to the Web Conference (WWW) 2026, one focused on intelligent blockchain optimization and another on agentic LLM decision-making. While the specific technical details are beyond this explainer, the themes point towards integrating LLM agents directly into the optimization and governance of decentralized infrastructure: for example, using LLMs to reason about network parameters, propose configuration changes, or mediate between competing objectives like latency, security, and cost.
Combined with multi-agent frameworks like SiriuS, this research suggests that LLMs will increasingly be deployed not just as interfaces to blockchain systems but as active participants in their evolution. Agentic LLMs could, for instance, simulate the impact of fee schedule changes, model validator incentives, or suggest new mechanisms for load balancing and congestion control. They could assist human protocol designers by generating candidate proposals, stress-testing them against historical data, and highlighting unintended consequences. As with trading agents, the challenge will be to harness their reasoning power while providing transparent, verifiable guardrails that keep ultimate control in human or onchain governance hands.
Infrastructure, APIs, and Verifiable AI
Behind every LLM agent lies a stack of infrastructure: GPUs or accelerators to run inference, network layers to route requests, and often cryptographic or hardware enclaves to ensure integrity and privacy. In crypto, this stack intersects directly with onchain systems as inference requests, payments, and proofs of correctness become part of decentralized workflows.
One axis of differentiation is between centralized and decentralized compute. Traditional cloud providers offer vast GPU clusters but require trusting the provider to run the requested model faithfully and to manage data securely. Decentralized GPU networks, by contrast, distribute workloads across many independent node operators, coordinated by token incentives and onchain rules. Aethir’s network is one such attempt, providing a decentralized GPU cloud whose resources can be accessed via APIs to run LLMs and other AI workloads. On top of this base layer, Aethir Mesh aims to “open the LLM API layer to everyone,” packaging access to top-tier open-source LLMs so that developers can build applications without directly managing GPU nodes.
Aethir Claw adds yet another layer, functioning as an AI agent hosting platform that provides fully isolated VPS environments, crypto-based payments, and bundled LLM API credits for frontier models from major providers like Claude, OpenAI, and Google. This design acknowledges that deploying an AI agent in the mid-2020s typically requires juggling multiple platforms—a VPS provider, an LLM API subscription, API key management, separate billing systems, and multiple dashboards—and seeks to consolidate them into a single subscription. For crypto projects, such platforms can reduce operational overhead while maintaining alignment with decentralized infrastructure and payment rails.
Verifiable and Trustless Inference
Trust in AI systems is not just about quality of outputs but about assurances that a particular model was actually run, that it was not tampered with, and that data was handled as promised. OpenGradient’s work on “trustless, verifiable AI inference” exemplifies this emerging category of infrastructure. Their x402 upgrade introduces mechanisms for verifiable inference that combine trusted execution environments (TEEs) with cryptographic protocols, enabling users to verify that an inference request was executed correctly without learning the model’s proprietary weights. Since launch, OpenGradient reports having processed over one million LLM inference requests through this x402-powered infrastructure, with inference requests settled through batched onchain payments to facilitate scalable execution for verifiable AI systems.
In a crypto context, such verifiable inference is more than a nice-to-have. If a DAO delegates governance decisions to an AI agent, token holders may demand proof that the agent is indeed using an approved model and configuration. If a DeFi protocol uses LLMs to score collateral or filter transactions for risk, counterparties will want assurances that these decisions are made according to disclosed criteria. Combining TEEs, cryptographic attestations, and onchain settlement can make AI inference auditable in much the same way that smart contracts make program execution auditable. This, in turn, opens possibilities for markets in “AI as a service” where buyers can trust outputs without trusting any single provider.
Cost Optimization Layers and Billing Abstractions
Even with efficient models and verifiable infrastructures, cost remains a bottleneck. Platforms and tools that explicitly target AI cost optimization are therefore gaining attention. TrueFoundry’s analysis outlines both tactical and architectural approaches, from careful prompt design to model routing, caching, and dynamic scaling of infrastructure based on load. In crypto, similar logic is being applied to agent fleets, where cost layers like GoPlus Costr aim to reduce AI agent costs by as much as 90% while preserving security and performance, for example by compressing prompts, reusing intermediate computations, and orchestrating calls across heterogeneous models and providers.
Such cost layers often sit alongside API routers, consolidating billing across many models and services into a unified dashboard and payment flow. For crypto firms and DAOs, paying LLM costs in stablecoins or native tokens, with transparent onchain accounting, aligns better with existing treasury management practices than traditional SaaS billing. As verifiable inference systems like OpenGradient show, it is even possible to settle inference requests via batched onchain payments, turning AI workloads into first-class onchain economic activity. This convergence of AI operations with DeFi primitives—escrow, streaming payments, token incentives—may prove to be one of the most durable intersections between LLMs and crypto.
Researchers find 26 LLM API routers secretly injecting malicious code and stealing developer credentials
UC researchers audited 428 third-party LLM API routers — intermediaries that sit between AI coding agents and model providers like Anthropic and OpenAI — and found 26 actively malicious: 9 injecting code into tool calls, 17 exfiltrating AWS credentials, and 1 draining ETH from a test wallet. The routers exploit the fact that they terminate TLS and see all plaintext payloads, yet no provider enforces cryptographic integrity between client and upstream model. The paper, "Your Agent Is Mine," is the first systematic study of this supply chain attack surface and highlights a growing risk for developers using AI agents for smart contract and wallet work.
LIFE resilient self-improving multi-agent LLM framework proposed
26 malicious LLM API routers discovered injecting code and stealing credentials
Google releases Gemma 4 open models: 256K context, multimodal, Apache 2.0
Agentic LLM decision-making and blockchain optimization papers accepted to WWW'26
Google launches Gemma 4 12B encoder-free model targeting local inference
Anthropic ships Claude Opus 4.7 with 3x coding gains at unchanged pricing
Risks, Attacks, and Governance Challenges
The integration of LLMs into crypto systems introduces new risks alongside new capabilities. Some risks are inherent to current LLM technology; others arise from the particularities of financial and blockchain environments.
At the model level, LLMs remain prone to hallucinations—confidently stating false facts or fabricating details—especially when operating outside their training distribution or without access to up-to-date data. They can misinterpret ambiguous instructions, overlook edge cases, or produce superficially plausible but logically inconsistent rationales. Their knowledge is often frozen at the time of training, which is particularly problematic in fast-moving markets where regimes shift and new protocols appear regularly. While retrieval-augmented generation and tool use can mitigate some of these issues by providing access to fresh data, the risk of subtle misinterpretation or omission remains.
When such models are given the ability to act—placing trades, adjusting risk parameters, or voting in governance—these limitations translate into operational risk. An agent might misread a liquidity pool’s fee structure and enter an unprofitable position, misinterpret a protocol’s upgrade proposal and advise voting against its own long-term interests, or fail to account for correlated risks across positions. Properly designed agent systems therefore incorporate multiple layers of oversight: human-in-the-loop checkpoints for critical decisions, quantitative risk limits enforced at execution layers, and sometimes multiple independent agents that cross-check each other’s recommendations before action. In other words, LLM agents should be treated more like junior analysts or automated runbooks than omniscient oracles.
LLM-Powered Exploits and Defensive Tools
Crypto’s adversarial environment amplifies another class of risk: the use of LLMs to automate or scale attacks. Models that are good at reading and writing code can be used to search for vulnerabilities in smart contracts, generate exploit payloads, or adapt existing attack techniques to new targets more rapidly. Socially, LLMs make it easier to generate convincing phishing messages, deepfake communications from project teams, or targeted scams that exploit the conversational style of trusted community figures. As AI-powered exploits surge, some security teams warn that both the speed and volume of attacks may increase, with attackers outsourcing much of the labor of reconnaissance, exploit development, and social engineering to automated systems.
At the same time, LLMs can be powerful defensive tools. Platforms like Firepan, which offers a DeFi vulnerability scanner enhanced by AI, show how models can be used to audit contracts, generate test cases, and flag suspicious patterns in codebases. Security researchers can use LLMs to quickly summarize complex code and identify likely risk points before deeper manual review. DeFi developers can integrate LLM-based linters or code reviewers into their CI pipelines, receiving natural-language explanations of potential issues. As with all AI tooling, these systems are not a replacement for expert human review, but they can act as force multipliers that raise the floor on security practices.
Governance, Regulation, and Ethical Considerations
The governance implications of LLM integration are subtle but profound. If DAOs begin to rely on AI agents as delegates or advisors, questions arise about accountability, alignment, and concentration of influence. If many token holders delegate to the same AI system—perhaps a popular digital twin of a respected researcher—the effective decision power might become concentrated in that system’s maintainers and creators. If an agent misjudges a proposal and causes economic damage, who bears responsibility: the model provider, the agent deployer, or the delegating token holders?
Regulators, too, are grappling with how to classify LLM-based agents. If an AI agent trades on behalf of users, is it an unlicensed investment advisor, a broker, or something new? If it manages a portfolio based on user prompts, does that trigger fiduciary duties, and if so, who owes them? Crypto complicates matters further by enabling pseudonymous deployment and cross-border operation, making traditional registration and oversight mechanisms harder to apply. Some jurisdictions may attempt to regulate AI-augmented trading activity under existing financial laws; others may focus on data protection, algorithmic accountability, or safety standards for high-risk AI systems.
Ethically, concerns include bias and fairness in decision-making, privacy of data used to train or prompt models, and the potential displacement of human roles. LLMs trained on historical market commentary or governance debates may inherit biases in whose voices are most represented, potentially skewing their recommendations in favor of incumbents or particular narratives. Digital twins of specific individuals raise questions about consent, control, and posthumous use of one’s digital traces. Crypto’s ethos of transparency and user sovereignty offers some tools to address these issues—for example, by making training data sources auditable or enabling users to fork and adapt AI agents under open licenses—but the emerging norms are still unsettled.
Conclusion
Large language models have moved from curiosity to critical infrastructure in just a few years. As systems that can ingest unstructured language, reason across complex inputs, and generate both human-readable explanations and machine-executable instructions, they provide a natural interface between the messy world of human narratives and the strict logic of code and smart contracts. In crypto and DeFi, this interface is particularly valuable: markets are narrative-driven, protocols are code-based, and information flows are overwhelming. LLMs are uniquely positioned to sit at this junction.
In this explainer, we have traced how LLMs work at a technical level, how the model and infrastructure landscape has evolved, and how these systems are being deployed in crypto contexts. We examined digital twin approaches that encode the research personas of top investors, multi-agent trading frameworks that emulate the structure of trading firms, and onchain operating systems like Virtuals EconomyOS that connect LLM agents directly to wallets and perp markets. We explored infrastructure trends, from decentralized GPU networks and integrated agent-hosting platforms like Aethir Mesh and Claw, to verifiable inference systems such as OpenGradient’s x402 that settle AI workloads via batched onchain payments. We also considered cost optimization strategies, privacy-preserving router layers like Qtum’s, and the emerging research on agentic LLM decision-making and blockchain optimization.
At the same time, we have highlighted the risks: hallucinations, misaligned incentives, LLM-powered exploits, governance concentration, and regulatory uncertainty. LLMs should not be treated as infallible oracles but as powerful, fallible tools whose outputs must be contextualized, checked, and constrained. Properly designed agent systems will incorporate multiple layers of oversight, verification, and onchain guardrails, much as responsible DeFi protocols employ audits, bug bounties, and formal verification.
For crypto builders, the key design questions are less about whether to use LLMs and more about how. Which parts of the stack should they inhabit: research, execution, risk, governance? What balance should be struck between local models and cloud APIs, between centralized and decentralized compute, between human and AI authority? How will verifiable inference, cost layers, and new token standards shape the economic and governance structures that emerge around AI-native DeFi?
- Smart-contract / protocolHigh
LLM-generated exploit tooling lowers the skill floor for DeFi attacks; the emergence of dedicated AI-powered vulnerability scanners (Firepan) confirms the threat is operationally real.
Researchers confirmed 26 production LLM API routers actively injecting malicious code and exfiltrating developer credentials, compromising the tooling layer before code ever reaches a smart contract.
- CentralizationHigh
Dependence on a handful of closed LLM API providers creates surveillance and single-point-of-failure risk that Vitalik's sovereign local stack explicitly targets as the next self-custody frontier.
Open-weight releases under Apache 2.0 reduce regulatory surface versus closed APIs, but AI-assisted DeFi exploits are likely to accelerate enforcement attention on the LLM-crypto intersection.
Stable closed-API pricing alongside rising open-weight capability compresses the moat of proprietary model providers and pressures AI infrastructure token valuations tied to exclusive model access.
Outlook
Over the coming years, LLMs are likely to become as ubiquitous in crypto tools as block explorers or DEX aggregators. As models improve in reasoning efficiency, as cost optimization layers mature, and as verifiable inference and decentralized GPU networks scale, the friction of deploying capable AI agents will continue to fall. Frontier models will push the envelope on complex reasoning and multimodal analysis, while open and local models like Gemma will give users privacy-preserving, offline options. Multi-agent architectures and self-improving frameworks such as SiriuS will allow agent fleets to learn from experience, gradually encoding the institutional memory of trading firms, funds, and DAOs.
For crypto markets, this will mean more automated, 24/7, and strategy-rich participation, with LLM agents arbitraging inefficiencies, monitoring governance, and scanning for risks at a scale humans cannot match. It will also mean new attack surfaces and governance challenges, as AI systems become both tools and actors within decentralized ecosystems. The most robust designs are likely to combine transparent onchain rules, verifiable AI infrastructure, and carefully scoped LLM agents whose power can be audited, limited, and, if necessary, revoked.
In that sense, the convergence of LLMs and crypto is less about replacing humans and more about re-architecting how humans, AI systems, and code coordinate. For a sector built on programmable money and open, composable infrastructure, LLMs offer a programmable narrative and reasoning layer—one that, handled wisely, can augment human judgment and expand what is practically governable and tradable on-chain.
Latest LLM news
Anthropic ships Opus 4.7 with 3x coding gains and tripled image resolution, holding pricing steadyFirepan opens $239/mo DeFi vulnerability scanner for free as AI-powered exploits surge, urging developers to secure codebases before LLM-driven attacks escalateResearchers find 26 LLM API routers secretly injecting malicious code and stealing developer credentialsVitalik Buterin unveils self-sovereign local LLM stack, prioritizing privacy, on-device inference, and secure data pipelines to eliminate reliance on centralized AI servicesGoogle releases Gemma 4 open models with 256K context and multimodal support under Apache 2.0 licenseGoogle launches Gemma 4 12B encoder-free AI model, signaling a major shift in local LLM approachSources
- https://www.ibm.com/think/topics/large-language-models
- https://github.com/tauricresearch/tradingagents
- https://x.com/mominsaqib/status/2064395096695374317
- https://arxiv.org/html/2503.02167v1
- https://aethir.com/blog-posts/introducing-aethir-claw-your-ai-agent-our-infrastructure
- https://www.opengradient.ai/blog
- https://x.com/Theta_Network/status/2052444490401538085
- https://www.truefoundry.com/blog/what-is-ai-cost-optimization
- https://x.com/olaxbt/article/2064728175570255936
- https://x.com/qtum/status/2064162701316866559
- https://io.net/blog/llm-fine-tuning-budget-guide-gpu-costs-timelines-and-what-to-spend
- https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/
- https://x.com/AethirCloud/status/2062836565219430450
- https://www.facebook.com/venturebeat/posts/researchers-automated-llm-reasoning-strategy-design-and-cut-token-usage-by-695/1363948928924984/
- https://www.anthropic.com/news/claude-opus-4-7
- https://arxiv.org/html/2502.04780v1
- https://x.com/AethirCloud/status/2054532416945963111
- https://x.com/guardian_swiss
- https://arxiv.org/html/2504.09059v1
Community notes
Spot something off or out of date? Drop a note. Editors review topic notes daily and roll accepted fixes into the explainer — contributors are recognized in the monthly $SQUID drop.
Loading notes…