
Explains what “outage” means in crypto, from exchange and blockchain stalls to AWS and Cloudflare failures, using recent cases like Coinbase, Sui, Base, Starknet, TON and X to unpack causes, market impact, and resilience strategies.
+12 sources across the wider coverage universe
 Coinbase experienced a system wide outage. Now resolved.2024-05
Coinbase experienced a system wide outage. Now resolved.2024-05 TON blockchain experienced over six-hour outage, halting block production and prompting Binance and Bybit to suspend transactions.2024-08
TON blockchain experienced over six-hour outage, halting block production and prompting Binance and Bybit to suspend transactions.2024-08 Base Incident report reveals infrastructure weakness behind outage2025-08
Base Incident report reveals infrastructure weakness behind outage2025-08 Base chain resumes block production after one hour outage2025-08
Base chain resumes block production after one hour outage2025-08 AWS Several major online services, including Coinbase, experienced access issues following a widespread disruption at Amazon Web Services2025-10
AWS Several major online services, including Coinbase, experienced access issues following a widespread disruption at Amazon Web Services2025-10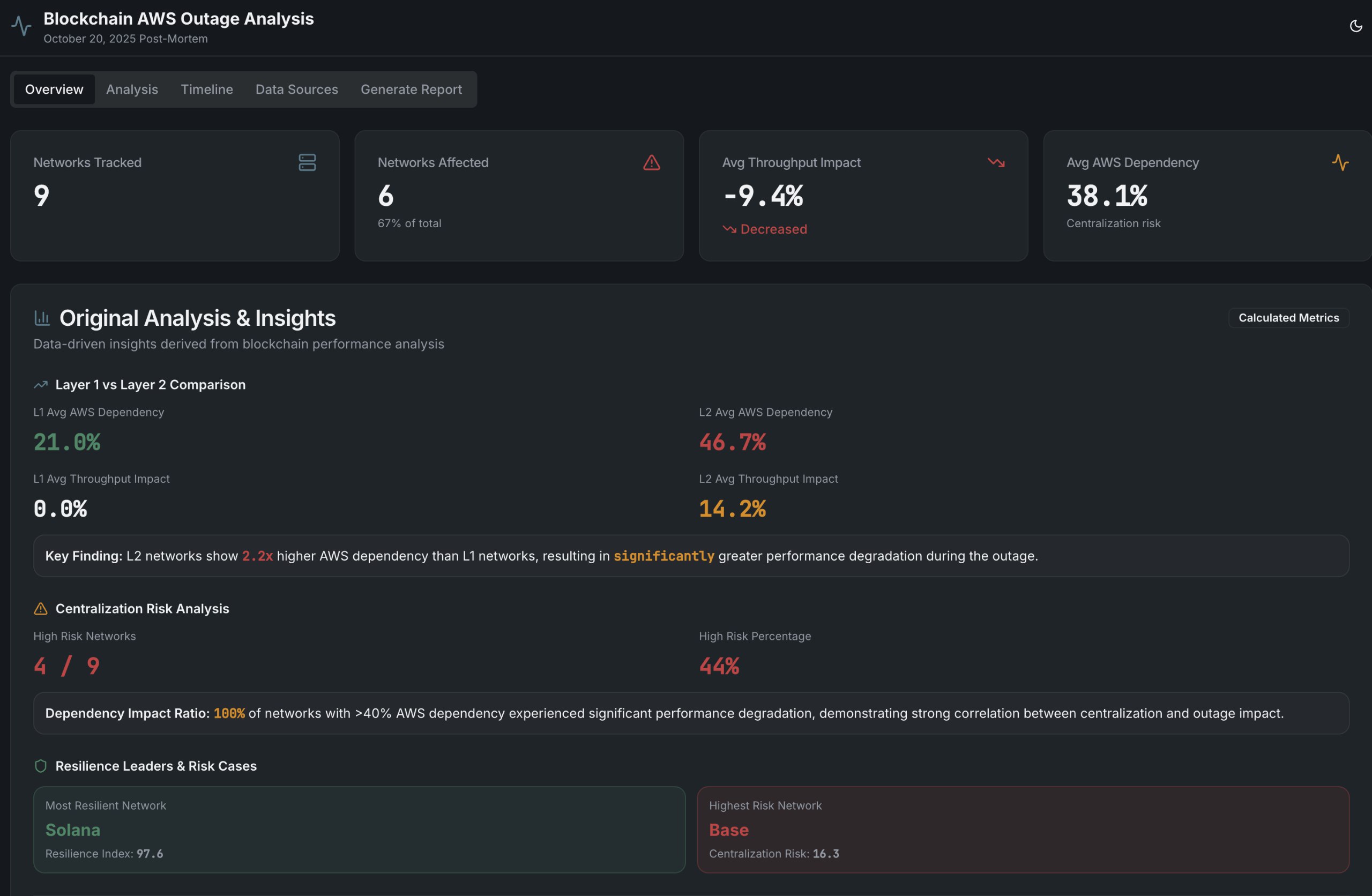 AWS Blockchain Tracker provides a post mortem analysis on the impact of the October 20th AWS outage on various chains. L1's such as Solana prove to be the least dependent on AWS, with L2's like Base being the most dependent.2025-10
AWS Blockchain Tracker provides a post mortem analysis on the impact of the October 20th AWS outage on various chains. L1's such as Solana prove to be the least dependent on AWS, with L2's like Base being the most dependent.2025-10
Outages in Crypto: Causes, Consequences, and How the Industry Adapts
An outage in crypto is any period when users or systems cannot reliably access blockchain networks, trading venues, or supporting infrastructure, whether due to software bugs, consensus failures, or external service disruptions. In a market that never sleeps, outages have become a defining test of how decentralized, resilient, and mature digital-asset ecosystems really are.
Outages are no longer rare edge cases in crypto but recurring stress tests across every layer of the stack, from centralized exchanges like Coinbase and Gate.io, to layer-1 networks such as Sui and TON, to Ethereum layer-2 rollups like Base and Starknet, and even the “web2” backbone of Amazon Web Services (AWS) and Cloudflare that so much of “web3” still depends on. Each incident reveals a different failure mode—ranging from consensus bugs and upgrade regressions to DNS misconfigurations and distributed denial-of-service attacks—and forces projects to reconsider how they architect redundancy, communicate with users, and handle compensation and liability. These outages also interact with broader financial markets and public perceptions, as seen when a massive outage at X (formerly Twitter), owned by Elon Musk, fed into wider concerns that contributed to a steep sell-off in Tesla shares. Understanding what outages are, why they happen, and how various players respond is now essential context for anyone trading, building, or regulating crypto markets.
What Is an Outage in Crypto?
In the most general sense, an outage is a failure of availability or correctness: the system is either not reachable at all, or it is reachable but cannot perform its intended function within acceptable performance or safety bounds. In crypto, this definition applies across several domains at once. It can mean that a blockchain’s consensus protocol has halted and blocks are no longer being produced, as occurred on the Sui and TON networks. It can mean that a centralized exchange (CEX) like Coinbase is online but temporarily unable to process deposits, withdrawals, or trades because its underlying cloud infrastructure has failed. It can also mean that users simply cannot reach a website or API because a content delivery network (CDN) like Cloudflare or a cloud provider’s DNS system is returning errors, even if the underlying blockchain nodes and contracts remain unaffected. From a user’s perspective, all of these situations collapse into a single experience: “the service is down.”
Crypto outages often straddle multiple layers simultaneously. A single AWS region failure in the United States can degrade or disable thousands of websites and APIs that host exchange frontends, wallet backends, and layer-2 infrastructure, which then creates second-order effects on trading and on-chain activity. When AWS us-east-1 experienced issues with DynamoDB and related DNS lookups, Coinbase reported that many of its services, including trading and transfers, were heavily impacted, and independent monitoring later showed that Base, Coinbase’s layer-2 network, was among the most visibly affected blockchains. Conversely, a blockchain-level stall, such as Sui’s multi-hour halt or TON’s six-hour consensus loss, can force exchanges and custodians to suspend transfers even if their own infrastructure remains healthy. In this way, outages propagate across a complex network of dependencies and create a blurred boundary between “web2” and “web3” reliability.
It is also important to distinguish between complete and partial outages. In some cases, a service is hard down: Coinbase’s October 2025 incident, for example, created periods in which key services were unavailable or severely impaired, including transfers, staking, and crypto send/receive. In other cases, the failure is more subtle. Base has experienced situations where its internal block production continued normally, but Ethereum mainnet state updates stalled for roughly 36 hours, which meant that bridging and settlement processes depending on those state updates were effectively frozen even though local user transactions appeared to be working. Similarly, Cloudflare’s November 18, 2025 outage resulted in degraded or failing service for a subset of customers due to a bug in its Bot Management logic, but the impact varied by configuration and region. From a risk perspective, these partial outages can be more insidious because they are harder to detect, explain, and compensate for.
In crypto, outages are particularly visible because users can often cross-check narratives. If an exchange claims “the network is down,” but on-chain explorers show blocks being produced normally and non-custodial wallets can still transact, users quickly question whether the exchange is using “network issues” as a euphemism for internal problems such as liquidity stress or risk-control triggers. Conversely, when networks like Sui or Starknet halt block production and post real-time updates and post-mortems, users can verify those claims through independent uptime dashboards and block explorers. This transparency cuts both ways: it exposes underprepared projects but also allows credible ones to demonstrate good incident response and recovery discipline.
Types of Outages Across the Crypto Stack
Outages in crypto can be classified along several dimensions, each corresponding to a different layer in the architecture. At the application and venue layer, centralized exchanges and brokerages experience outages when trading engines, order books, or custody systems become unavailable. Coinbase’s May 7 outage, attributed to an AWS data center failure, disrupted trading, deposits, withdrawals, and other core services for about eight hours, followed by a longer tail of degraded service until full recovery. Gate.io similarly experienced an exchange outage that prompted it to commit to compensating customer losses, albeit with the qualifier that “market factors” would be excluded from the compensation calculus. These events resemble outages at traditional exchanges such as the Australian Securities Exchange (ASX), whose high-profile system failures and botched settlement-system upgrade have drawn scrutiny from Australia’s corporate regulator and triggered legal action.
At the protocol layer, layer-1 and layer-2 blockchains experience outages when block production halts, consensus cannot be reached, or finalized state diverges and must be reorganized. Sui’s mainnet saw several such incidents, including a January 2026 consensus bug that halted block production for over six hours, a gas-charging logic crash that caused nearly six hours of downtime, and a subsequent stall linked to an interim fix for that same logic. TON, the blockchain associated with Telegram, suffered an outage exceeding six hours during which no new blocks were generated, reportedly due to abnormal load that prevented multiple validators from cleaning up old transactions, ultimately causing a loss of consensus. Ethereum layer-2 networks such as Starknet and Base have also experienced rollup-specific outages, including a nine-hour Starknet halt with two chain reorganizations after an upgrade and multiple Base incidents tied to sequencer behavior and infrastructure dependencies.
Below the protocol layer, infrastructure outages involve cloud providers, CDNs, DNS systems, and RPC relay networks. AWS outages, especially in the heavily used us-east-1 region, have repeatedly demonstrated how dependent crypto remains on centralized hosting. An AWS disruption affecting DynamoDB and DNS caused cascading slowdowns across 58 services globally and visibly degraded performance for Coinbase, several trading platforms, and multiple Ethereum layer-2 networks. Cloudflare’s November 2025 incident, triggered by an error in Bot Management configuration, interrupted connectivity for customers relying on Cloudflare’s edge network, including many crypto frontends and APIs. These events often leave underlying blockchains untouched while making them practically unreachable for most non-technical users.
Finally, there are information and social infrastructure outages, exemplified by X (formerly Twitter) going offline during what Elon Musk described as a massive DDoS attack by a group called DarkStorm, an event that coincided with a sharp, roughly 14% one-day plunge in Tesla shares and raised questions about operational resilience. While such outages are not “crypto outages” in a narrow sense, they affect crypto markets by disrupting news flow, social sentiment, and the functioning of bots and arbitrage systems that rely on real-time signals from social platforms. The interplay between these outages and token markets reinforces that crypto operates within a broader digital ecosystem whose weakest link can trigger cascading effects.
Detection, Monitoring, and the Role of Public Dashboards
Outages are detected through a combination of internal monitoring, external status pages, blockchain explorers, and third-party aggregators. For networks like Sui and Starknet, validators and core developers maintain public uptime dashboards and incident reports that record when block production stalls or transaction throughput drops to near zero. Sui’s status page, for example, flagged a major outage for mainnet validators starting around 07:15 PDT during its May stall, and block explorers such as Suiscan showed no new checkpoints or blocks for nearly an hour, indicating a complete halt in transaction finality. Starknet’s incident report for its September 2, 2025 outage provides a detailed timeline, from the initial impact shortly after the v0.14.0 upgrade through the two reorgs required to recover and the resubmission of roughly 1.5 hours of transactions.
For centralized services like Coinbase, AWS, or Cloudflare, internal telemetry is supplemented by public status pages and third-party services like Downdetector. Coinbase’s October 2025 post-mortem makes clear that the AWS DynamoDB failure impaired its ability to scale to meet traffic and maintain visibility into operational health, resulting in periods where services were hard down. Users who could not log in or transact often turned to sites like Downdetector, which aggregates user-submitted reports of outages and can quickly signal whether an issue is isolated or widespread. Downdetector’s dashboards frequently show correlated spikes across multiple platforms during large AWS or Cloudflare incidents, helping users infer that the problem is at the infrastructure level rather than with a single application.
Specialized blockchain monitoring firms such as Metrika have emerged to analyze the impact of major infrastructure outages on blockchain networks. In the wake of the October 20 AWS incident, Metrika’s post-mortem highlighted that the most visible blockchain impact occurred on Base, which saw degraded performance as its infrastructure providers grappled with DNS issues affecting DynamoDB in us-east-1. This kind of analysis, combined with Cloudflare and AWS’s own incident write-ups, allows the community to piece together cross-cutting narratives about how outages propagate across layers and geographies. In the long run, standardized uptime reporting and shared telemetry across crypto projects may become as important for trust as proof-of-reserves audits.

Leviathan News marked safe from global Cloudflare outage


Lego
Readers click outage stories as proof-of-centralization moments — the top stories all expose how supposedly decentralized infrastructure (Base on AWS, Coinbase on AWS, TON validators) fails through the exact same single points of failure as traditional finance.↗
Technical Root Causes: From Software Bugs to Cloud Failures
Behind every outage lies a chain of technical causes and design decisions. In crypto, these range from straightforward software bugs introduced during upgrades, to complex race conditions in cloud services, to emergent failures caused by abnormal load patterns and unexpected cross-system interactions. Understanding these root causes helps explain why outages remain stubbornly recurring—even as the industry gains experience—and highlights where architectural improvements are most needed.
Software Bugs and Upgrade Regressions
Many crypto outages are triggered in the aftermath of protocol upgrades. The logic is simple: new code paths, new configurations, and new integrations expose latent bugs that testing and staging did not catch. Sui’s sequence of outages in 2026 is a textbook illustration. The network’s May incident was tied to version 1.72, which introduced new address balance and gas charging logic. According to the Sui team, both the initial halt and a subsequent stall the next day were due to the interaction of this new gas logic with an interim fix that was designed to restore functionality quickly but carried a low-probability risk of causing further disruption. That low-probability risk materialized, forcing Sui developers and validators to roll out a longer-term software fix and coordinate its adoption across the mainnet.
Starknet’s September 2, 2025 outage after upgrading to version 0.14.0 (Grinta) similarly reflects the fragility of upgrades in complex, cross-chain environments. Once the new version was deployed, Starknet experienced approximately nine hours of degraded or halted service, culminating in the need to perform two chain reorganizations to restore normal operation. The incident report traces this back to a sequence of three interconnected issues, starting with failures in Ethereum RPC providers at the node logic level, which then cascaded into block production and finality problems on Starknet itself. The ultimate effect was that all transactions in affected blocks reflecting about 1.5 hours of activity were not processed and had to be resubmitted. Even though the system was eventually restored and the fixes increased network resilience, the episode underscores how upgrading a rollup is not just about its internal code but also about its dependencies on upstream and downstream services.
Ethereum layer-2 networks like Base have faced upgrade-related issues as well. After Base activated its Azul mainnet upgrade, reports indicate that Ethereum mainnet state updates stalled for roughly 36 hours, even though Base’s own block production and user transactions continued normally throughout this period. This meant that from the perspective of applications bridging between Base and Ethereum mainnet, the system was in a kind of split-brain state: locally responsive but globally inconsistent, raising questions about the semantics of “liveness” in multi-domain architectures. These kinds of regressions are particularly tricky to explain to users because the symptom is not a total halt but a mismatch between what users see in one domain and what eventually settles in another.
These examples highlight that upgrade discipline is as important in crypto as in any other distributed system. Comprehensive testing, canary deployments, and phased rollouts can reduce risk, but certain bug classes emerge only under the full complexity of mainnet traffic and adversarial conditions. For this reason, some protocols are experimenting with more conservative change management, extended testnet cycles, and formal verification of critical components such as consensus and fee-calculation logic. Others are embracing mechanisms such as feature flags and emergency kill switches for newly introduced modules, so that specific features can be disabled without halting the entire network. The challenge is to strike a balance between rapid innovation—which is central to crypto’s competitive dynamics—and operational stability, which markets and regulators increasingly demand.
Consensus Failures and Network Stalls
While upgrade bugs often manifest immediately after a deployment, some outages stem from the underlying consensus mechanisms that keep blockchains synchronized. Consensus failures typically take one of two forms: a halt, where the network stops producing blocks because it cannot reach agreement, or a fork, where conflicting views of history diverge and must be reconciled through reorganizations or manual interventions.
Sui’s January 2026 incident is an example of a consensus-induced halt. In that episode, validators submitted conflicting transactions to the protocol’s checkpoint mechanism, and the network was unable to reach the necessary threshold for consensus, leading to a more than six-hour stoppage in block production. According to Sui’s post-mortem, checkpoint certification and quarantine mechanisms detected the inconsistency and prevented any user-visible fork at the cost of halting progress. The team emphasized that user funds were never at risk and that no certified transactions were rolled back, but the trade-off was clear: the system chose safety over liveness until operators could diagnose and fix the issue.
TON’s outage illustrates a different path to consensus failure. The network experienced a six-hour gap in block production when an abnormal surge in load caused multiple validators to struggle with cleaning up their databases of old transactions. This backlog ultimately led to a loss of consensus, and the blockchain stopped generating new blocks at around 10:11 p.m. UTC. Exchanges like Binance and Bybit responded by temporarily suspending deposits and withdrawals to TON, explicitly citing the block production outage and advising users to await resolution. In TON’s case, the outage was not triggered by a protocol upgrade but by the interplay between workload patterns and validator resource management.
Starknet’s need for two reorgs during its September 2025 incident highlights yet another dimension of consensus complexity. When rollups reorganize, they are effectively revising their own history in light of new or corrected information, and any transactions in discarded blocks must be replayed or resubmitted. While Ethereum has long handled small reorgs as part of normal operation, extended reorgs across multiple layers and chains introduce new user-facing risks, including confusion about whether a transaction “really went through” and exposure to replay or sandwich attacks in adversarial settings. For this reason, some rollup teams are exploring stronger finality guarantees and checkpointing mechanisms that reduce the scope of possible reorgs at the cost of slower confirmation in edge cases.
These consensus-related outages underscore that decentralization does not automatically guarantee high availability. Byzantine fault-tolerant protocols are designed to withstand some amount of faulty behavior and communication delays, but they are still vulnerable to logic bugs, resource exhaustion, and misconfigured parameters that push them into unsafe or stalled states. Robustness requires not just theoretical security proofs but also operational practices, diverse implementations, and conservative assumptions about network and validator behavior.
AWS and the Centralization of Crypto’s Infrastructure
Even as many blockchains aim for decentralization at the protocol level, the infrastructure hosting nodes, APIs, and exchange backends remains highly centralized, with AWS playing an outsized role. When AWS suffers a regional or service-specific outage, the impact on crypto can be immediate and widespread. The October 20, 2025 incident involving DynamoDB and DNS in the us-east-1 region is a case in point: according to Amazon’s status page and third-party monitors, a misconfigured DNS subsystem in the DynamoDB control plane caused lookup failures that rippled across 58 services globally. As a result, thousands of applications that depended on DynamoDB—including some of Coinbase’s core services—experienced downtime or severe degradation.
Coinbase’s retrospective on the event describes how at 2:51 a.m. ET, AWS services dependent on DynamoDB began to fail, impairing Coinbase’s ability to scale with traffic and maintain visibility into its systems. Transfers, withdrawals, deposits, staking, onboarding, market data, and crypto send/receive were all impacted during the incident, with periods where services were effectively hard down. Full restoration of all Coinbase services occurred around 6:45 p.m. ET, after AWS implemented fixes to multiple systems, including improvements to EC2 network state propagation that had been a bottleneck. This timeline reveals how a cloud provider’s internal repair process can define the bounds of a crypto platform’s outage window, regardless of that platform’s own engineering competence or redundancy planning.
The crypto community’s attention to AWS risk intensified when independent analyses showed that certain networks were more affected than others. Metrika’s post-mortem called out Base as the most visibly impacted blockchain network during the October 20 AWS outage, in part because of its heavy reliance on infrastructure providers that were themselves concentrated on AWS in us-east-1. CryptoSlate similarly highlighted that Coinbase, Robinhood, and several Ethereum layer-2s experienced disruptions tied to the AWS fault, which exposed how many “decentralized” systems are still critically dependent on a single company’s cloud services. Video explainers on the event detailed how a race condition involving a DNS writer process in AWS led to inconsistent network state propagation, making even newly launched EC2 instances lack the necessary connectivity, and underscored that regional concentration in us-east-1 meant that seemingly global apps had hidden single points of failure.
The lesson from these episodes is not that AWS is uniquely unreliable but that structural dependencies matter. If most of the world’s crypto exchanges, wallet APIs, and layer-2 sequencers are hosted in the same cloud region, an outage there becomes tantamount to a systemic event. From a risk-management perspective, the solution involves multi-region and multi-cloud architectures, aggressive use of redundancy across providers, and designing systems that can degrade gracefully or switch over during infrastructure incidents. Coinbase’s own response—planning a regional redundancy overhaul after its May and October outages—reflects this shift in thinking. As regulators pay more attention to operational resilience, cloud concentration risk is likely to become a formal part of their oversight frameworks.
Cloudflare, CDNs, and DNS as Hidden Single Points of Failure
While AWS dominates compute and storage, Cloudflare and similar CDNs sit at the front door of many crypto applications, handling DNS resolution, TLS termination, caching, and security filtering. When they fail, users may see generic “site unreachable” errors even if the underlying origin servers and blockchains are functioning properly. Cloudflare’s November 18, 2025 outage illustrates how a local configuration bug can cascade into a global user-visible event. In that incident, a defect in the generation logic for Cloudflare’s Bot Management rules led to incorrect configuration being deployed, which then caused widespread service disruption for customers relying on those features. Cloudflare’s post-mortem details how the bug propagated through internal pipelines and how the company worked to rollback and stabilize systems, but from users’ vantage point, many sites simply stopped working or became intermittently unreachable.
For crypto, outages like this are a reminder that decentralization at the protocol level does not automatically translate into decentralized access. Many DeFi frontends, exchange portals, and wallet dashboards are behind Cloudflare for DDoS protection and performance reasons. When Cloudflare falters, these services vanish from the public internet, even though non-custodial users could still interact directly with smart contracts or nodes if they had the technical capabilities. This creates a functional centralization of user access at the CDN and DNS layers. Some crypto media outlets and technical teams have started designing their infrastructure to be resilient to such outages, using alternative DNS providers, static mirrors, or decentralized hosting for critical information, and at least one outlet publicly noted being “marked safe” from a global Cloudflare outage due to such choices. Even so, the dominant pattern remains one of reliance on a few large infrastructure companies whose failure modes extend beyond crypto.
DNS itself, independent of CDNs, is another underappreciated source of outage risk. The AWS incidents discussed earlier were exacerbated by DNS misbehavior in the DynamoDB control plane, which turned internal database issues into network-wide resolution failures. From an architectural standpoint, DNS problems are sometimes more disruptive than application-level bugs because they prevent even healthy systems from being reached. The recurring trope “it’s always DNS” may be a joke among engineers, but in the context of crypto, it underscores that many outages attributed to “network congestion” or “cloud issues” are, at root, failures of name resolution and routing that sit beneath the application and protocol layers.
Attacks, DDoS, and Malicious Events
Not all outages are accidents. Some are the result of deliberate attacks that aim to overload, disrupt, or compromise systems. In traditional finance and web platforms, DDoS attacks are a well-known threat vector, and crypto is no exception. What makes the X outage associated with the DarkStorm group noteworthy is both its scale and its broader repercussions. Elon Musk publicly characterized the event as a massive, coordinated DDoS assault, potentially with state-level involvement, which temporarily barred users worldwide from accessing X. While the immediate impact was on social media, the outage quickly fed into negative sentiment around Musk’s stewardship and the robustness of his platforms, with Tesla shares plunging about 14% in their worst day in five years and wiping out a large amount of market value since late 2025. This incident demonstrates how outages caused by attacks can erode investor confidence even when the underlying business model is unchanged.
In crypto, DDoS and other attack-driven outages often target RPC endpoints, exchange APIs, or nodes rather than the consensus layer itself. Attackers may flood public APIs to prevent price feeds from updating, interfere with arbitrage strategies, or create confusion during volatile market conditions. While there are fewer publicly documented cases in the provided sources of layer-1 consensus being knocked offline by pure DDoS, many projects treat such scenarios as realistic and invest in rate-limiting, traffic scrubbing, and multi-provider failover for their public interfaces. At the same time, governance attacks, smart contract exploits, and key compromises can cause “logical outages” where services are deliberately paused by operators to contain damage or prevent further loss, even though the underlying infrastructure is technically functional. In these cases, the line between security incident and service outage blurs.
As crypto markets grow more interconnected with traditional finance and as the stakes rise, the incentive for sophisticated adversaries to target critical infrastructure—including cloud providers, DNS, and major venues—also increases. This trend suggests that incident response in crypto must increasingly integrate threat intelligence and security operations, not just reliability engineering. Outages triggered by attacks may be harder to predict and quicker to escalate, making playbooks, tabletop exercises, and cross-organization coordination essential.
Economic and Market Impacts of Outages
Outages are not merely technical curiosities; they reshape markets in real time. When traders cannot execute strategies, when funds are temporarily stuck in limbo, or when sentiment shifts due to perceived fragility, prices, volatility, liquidity, and even regulatory trajectories can change. Each major outage provides a case study in how market participants react and how those reactions feed back into design and policy.
Price Reactions, Liquidity Shocks, and Volatility
Token prices often respond swiftly to network-level outages because these events alter the perceived risk profile of the asset. When Sui’s mainnet stopped producing blocks on May 28, 2026, the network stall coincided with an immediate market reaction: SUI’s price dropped around 8% as trading incorporated the new information about the protocol’s reliability. The fact that explorers showed no new checkpoints or blocks and the official status page flagged a major outage reinforced the view that this was not a transient glitch but a serious technical failure. While SUI had previously recovered from other incidents after patches and post-mortems, repeated outages in a short period can lead to a structural risk premium as traders demand compensation for operational uncertainty.
TON’s six-hour outage offers a complementary perspective. During the stoppage, the network processed no transactions, and data from Tonscan indicated no new blocks after around 10:11 p.m. UTC. Major exchanges like Binance and Bybit suspended deposits and withdrawals to TON, effectively isolating the network from broader liquidity flows. Price behavior during such windows can be distorted: existing positions on exchanges might trade, but the inability to move tokens on-chain or between venues constrains arbitrage and can lead to wider spreads and localized volatility. Even if the final price impact is modest once service resumes, these transient dislocations can be painful for market makers and leveraged traders.
Centralized exchange outages have their own characteristic effects. Coinbase’s May and October 2025 incidents, tied to AWS failures, limited user access to trading and transfers for hours. During these periods, liquidity on Coinbase order books shrank, and traders unable to access the platform had to either sit out market moves or route through other venues if they had accounts there. In a multi-exchange ecosystem, outages at a single venue can shift order flow and price discovery to competitors, but they can also create fragmentation and momentary cross-exchange price gaps if arbitrageurs are constrained by stuck deposits or unavailable APIs. The net effect often includes temporarily higher volatility, reduced depth, and a perception that operational risk must be priced alongside market risk.
Even outside pure crypto, outages can ripple into asset prices by affecting perceptions of management quality and systemic robustness. X’s outage, framed as a massive cyberattack, raised questions about the platform’s resilience and Musk’s strategic choices, contributing to negative sentiment around Tesla and a one-day 14% share price plunge. While many factors drive large-cap equities, the optics of a flagship platform going dark can sharpen investor focus on governance and risk controls—a dynamic likely to apply to large crypto exchanges and protocol treasuries as they become more intertwined with traditional capital markets.
User Experience, Trust, and Contagion of Confidence
For everyday users, the most tangible effect of an outage is frustration and loss of trust. When Coinbase goes down for several hours during peak trading, users experience not only missed opportunities but also anxiety about the safety of their funds and the platform’s competence. Coinbase’s October 2025 retrospective acknowledges this human dimension by emphasizing its commitment to improving regional redundancy and operational transparency after AWS-related disruptions. Similarly, when Sui or Starknet halt and require reorgs or coordinated validator upgrades, developers building on these networks must reckon with the possibility that their dApps will periodically be unusable or that user transactions will need to be resubmitted.
Trust erosion can be contagious. CryptoSlate’s coverage of the AWS failure emphasized that several major blockchains and trading platforms experienced disruptions and framed the incident as exposing crypto’s centralized weak points. When multiple networks and venues go down together, users may generalize their distrust from a single project to the broader ecosystem, reinforcing narratives that digital assets are inherently unstable or dependent on a fragile web2 infrastructure. This perception is particularly potent in the context of decentralized finance, where one of the core value propositions is nonstop, permissionless access. If users repeatedly find that frontends are unreachable due to Cloudflare or AWS issues, or that bridges are paused due to L2 sequencer problems, they may question the practical difference between DeFi and traditional platforms with fixed trading hours and known circuit breakers.
Exchange compensation policies can either mitigate or exacerbate trust issues. Gate.io’s decision to compensate users for outage-related losses “excluding market factors” is a nuanced attempt to draw a line between losses directly caused by service unavailability and those driven by ordinary price movements. On one hand, this can reassure users that grossly unfair outcomes—like forced liquidations triggered solely by an inability to close positions due to an outage—will be addressed. On the other hand, the ambiguous phrase “market factors” leaves room for dispute about which losses qualify, especially in a market where outages and price volatility are often intertwined. Clear, pre-defined outage policies, including how compensation is calculated and under what conditions, may become a competitive differentiator among centralized platforms.
Systemic Risk, Regulation, and Accountability
As outages grow larger and more frequent, they naturally attract attention from regulators and policymakers. TradFi provides a reference point: the Australian Securities Exchange’s repeated tech failures and a failed upgrade to its settlement system have so eroded confidence that Australia’s corporate regulator has launched legal action, alleging misleading conduct and governance shortcomings. One high-profile outage before Christmas led to a 6% drop in ASX’s shares and intensified scrutiny of its risk management and oversight. This case illustrates that in regulated markets, operational failures can translate into legal liability, capital market penalties, and potentially structural reforms.
For crypto, the regulatory conversation around outages is still evolving, but several themes are emerging. Cloud concentration risk, highlighted by AWS incidents impacting Coinbase, Base, and multiple other platforms, is likely to become a focus area for prudential regulators concerned about single points of failure in financial market infrastructure. Operational resilience frameworks—like those being considered or implemented in traditional finance, such as Europe’s Digital Operational Resilience Act (DORA)—could be extended to systemically important crypto service providers, requiring them to meet specific uptime targets, diversify critical dependencies, and maintain tested recovery plans. The more that centralized exchanges and large custodians integrate with banking systems, the more likely it is that regulators will treat major outages as reportable incidents akin to payment system failures.
At the protocol level, accountability is more diffuse but not absent. Governance tokens, foundations, and core development teams may face reputational and, in some jurisdictions, legal consequences if they are deemed to have misrepresented the robustness of their systems or failed to address known vulnerabilities. Sui, Starknet, and other networks have responded to outages by publishing detailed incident reports, roadmaps for remediation, and assurances that no user funds were lost. These post-mortems serve both technical and political functions: they build trust with developers and validators, but they also create a record that could be scrutinized by regulators or courts in the future. Transparent communication may not eliminate liability, but it demonstrates good-faith efforts to meet emerging standards of care.
In the long run, the interplay between outages, market discipline, and regulation will shape how crypto infrastructures are governed. Markets can punish unreliable projects through price declines and loss of volume, as seen in SUI’s drawdowns after repeated outages, but there may be limits to how much risk can be managed purely through investor awareness. Where outages threaten broader financial stability or harm retail users who lack the sophistication to assess operational resilience, regulators are likely to intervene, at least for centralized intermediaries and potentially for some protocol-level actors with significant control over critical components.
AWS Blockchain Tracker provides a post mortem analysis on the impact of the October 20th AWS outage on various chains. L1's such as Solana prove to be the least dependent on AWS, with L2's like Base being the most dependent.
"Key findings from the outage include the resilience of major Layer 1 (L1) blockchains like Ethereum, Solana, and Avalanche, which maintained 100% uptime despite varying levels of AWS dependency [Decrypt, CryptoSlate, Brave New Coin]. In contrast, Layer 2 (L2) networks such as Base, Arbitrum, Optimism, Polygon, Linea, and Scroll experienced degraded performance, with throughput reductions ranging from -8% to -25% [Decrypt, CryptoSlate]. The outage also caused specific disruptions in the crypto ecosystem, including MetaMask users reporting zero balances due to Infura outages [Decrypt], and Coinbase experiencing login failures and trading halts [Fortune Crypto, CNBC]."
- 01AWS dependency exposed↗
The post-mortem ranking L2s as most AWS-dependent and L1s like Solana as least hit a raw nerve about decentralization being architecturally hollow for rollups.
- 02Major exchange downtime↗
Coinbase's system-wide outage and Gate.io's compensation-with-a-catch showed readers that custodial access is never guaranteed, even at top-tier venues.
- 03L2 reliability crisis↗
Back-to-back Base outages with an incident report admitting infrastructure weakness deepened reader skepticism about whether rollups are production-ready.
- 04Post-outage accountability gaps↗
Gate.io's compensation caveat and Base's infrastructure admission showed readers that 'resolved' rarely means 'made whole' or 'fixed the root cause.'
- 05Cyberattack-driven outages↗
DarkStorm's DDoS taking down X, confirmed by Musk as possibly state-level, reframed outages from accidents to deliberate attacks on critical infrastructure.
- 06Regulatory fallout from failures↗
The ASX regulator inquiry after a botched upgrade outage showed readers that sustained outages at financial infrastructure attract governance investigations, not just apologies.
Case Studies Across the Stack
Examining specific outages in detail reveals recurring patterns and distinct lessons. Across Coinbase’s exchanges, Sui’s layer-1, Base and Starknet’s rollups, TON’s consensus, Cloudflare’s edge, and X’s social infrastructure, we see different manifestations of the same underlying challenge: keeping complex, interdependent systems reliably online under imperfect conditions.
Coinbase: Exchange Outages in the Shadow of AWS
Coinbase occupies a dual role in the crypto ecosystem as both a regulated exchange and a major infrastructure operator, running the Base layer-2 network and providing custody and market data services. Its outages, therefore, reverberate widely. The exchange’s May 7 outage and the October 20, 2025 incident linked to AWS illustrate how deeply Coinbase’s operational continuity is intertwined with Amazon’s cloud.
On May 7, Coinbase experienced an outage lasting about eight hours that disrupted trading, deposits, withdrawals, and other core user-facing services. A post-event report attributed the root cause to a failure at an AWS data center, which impaired Coinbase’s infrastructure and led to cascading unavailability across its product lines. While Coinbase restored service and later released an outage report outlining regional redundancy upgrades, the episode revealed the ways in which even a technologically sophisticated exchange remains exposed to its cloud providers.
The October 20, 2025 event was even more structurally revealing. Starting at 2:51 a.m. ET, AWS services dependent on DynamoDB experienced widespread failures due to a DNS issue in the DynamoDB control plane. Coinbase’s systems, built on top of these services, struggled to scale with traffic and to maintain internal observability, leading to a prolonged period of degraded and, at times, fully unavailable services. CryptoSlate reported that Coinbase, Robinhood, and several Ethereum layer-2 networks all experienced disruptions during the AWS outage, underscoring the concentration of risk in AWS’s us-east-1 region. A detailed YouTube analysis explained how a race condition in AWS’s DNS writer caused inconsistent network state propagation, preventing new EC2 instances from having correct connectivity—an issue that affected not just Coinbase but an estimated 35,000 services worldwide.
Coinbase’s own post-mortem describes a clear set of “next steps,” including implementing more robust multi-region architectures, increasing redundancy for critical databases, and enhancing their ability to fail over away from compromised AWS services. These plans reflect a broader shift in thinking among major crypto platforms: outages are no longer treated as one-off misfortunes but as evidence that current architectures must be hardened against both cloud-specific and multi-layer failures. How quickly and thoroughly Coinbase executes on these plans will likely influence not only its own reliability but also market expectations for other exchanges.
Sui: A Young Layer-1’s Triple Outage
Sui is a relatively new layer-1 blockchain whose design emphasizes high throughput and object-centric programming. As with many emerging protocols, its path to maturity has been punctuated by outages that reveal both its strengths and its rough edges. In January 2026, the Sui network went offline for over six hours due to a consensus bug that prevented validators from reaching agreement on checkpoints. Validators had submitted conflicting transactions to the checkpoint mechanism, and while Sui’s checkpoint certification and quarantine systems successfully prevented a user-visible fork, they did so at the cost of halting block production until operators could resolve the inconsistency. The Sui team emphasized that user funds were never at risk and that no certified transactions were rolled back, but the incident highlighted the trade-off between safety and liveness and the importance of robust consensus implementation.
In May 2026, Sui experienced another high-profile outage when its mainnet stopped producing blocks on May 28. The network stall triggered an approximately 8% drop in SUI’s price as traders reacted to the news and uncertainty about resolution timelines. Sui’s official status page flagged a major outage starting around 07:15 PDT, and explorers such as Suiscan showed no new checkpoints or blocks for nearly an hour, confirming that transaction finality had effectively halted. Engineers identified the issue within about 20 minutes and began deploying a solution, while public RPC nodes remained technically operational but could not settle transactions because validator coordination was impaired. Over the course of the next several hours, the network was gradually restored, with the core team emphasizing that user funds remained safe and that a detailed post-mortem would be provided.
Compounding matters, Sui faced a second major outage less than 24 hours after this stall. According to subsequent reporting, Sui’s mainnet validators experienced disruptions on consecutive days, both tied to the 1.72 release, which had introduced new address balances and gas charging logic. The first halt had been addressed with an interim software fix meant to quickly restore functionality, but that fix turned out to carry a low-probability risk of causing another network disruption, which is exactly what occurred. The Sui team responded by rolling out a long-term fix that was ultimately implemented by a majority of validators, stabilizing the network. From a governance and engineering perspective, this sequence illustrates the tension between rapid recovery and cautious, thoroughly tested patching.
Over time, Sui’s handling of these outages—through real-time communication, openness about root causes, and iterative improvements to testing and detection—may help restore confidence among developers and users. However, repeated outages in a relatively short period create a reputational drag that manifests in token pricing and partner hesitation. For Sui and similar networks, the path forward likely involves not only technical hardening but also more conservative upgrade strategies and possibly stronger on-chain or social safeguards around deploying consensus-critical changes.
Base and Other Ethereum Layer-2 Outages
Base, an Ethereum layer-2 network built on the OP Stack and incubated by Coinbase, exemplifies both the promise and the fragility of rollup-based scaling. Because Base’s sequencer and infrastructure are more centralized than Ethereum’s base layer, its availability profile can differ significantly from that of the mainnet. In 2024, Base experienced an approximately 12-hour sequencer outage caused by an Ethereum chain split, which temporarily halted block production and left user transactions pending. While the network eventually resumed normal operation, the incident highlighted how L2s can inherit and amplify L1-level issues if their sequencer design and failover mechanisms are not sufficiently robust.
In October 2025, AWS’s DynamoDB and DNS issues hit Base particularly hard. Metrika’s post-mortem describes how the AWS outage, though global in scope, had its most visible blockchain impact on Base, whose infrastructure providers struggled with DNS lookup failures in the us-east-1 region. During the disruption, Base’s performance degraded, and some services dependent on its RPC endpoints and bridging infrastructure experienced delays or intermittent unavailability. Base thus became a case study in how cloud concentration and rollup architecture can combine to produce distinctive outage patterns: even if the underlying Ethereum mainnet is operating normally, an L2 built atop AWS-centric infrastructure can become separately unreliable.
Another incident involved Base’s Azul mainnet upgrade. After Azul was activated, Ethereum mainnet state updates from Base stalled for about 36 hours, even as Base’s own block production and user-facing transactions continued normally. In practice, this meant that activities confined entirely to Base seemed unaffected, but any process requiring synchronization with Ethereum—such as bridging, settlement, or certain cross-chain protocols—was effectively blocked by the stalled state updates. The incident underscores how, in multi-domain architectures, liveness must be defined not only by local block production but also by the timely propagation of state to other chains.
The broader lesson from Base and kindred rollups is that their outage profiles differ from both exchanges and layer-1 networks. Sequencer centralization, dependency on specific infrastructure providers, and the need for cross-chain synchronization introduce new failure modes that are not fully captured by traditional notions of “network downtime.” As research and industry reports have noted, maturing ecosystems like Bitcoin, Ethereum, and Solana face increasing centralization and outage risks in specialized use cases—such as rollups, liquid staking, and cross-chain bridges—even if their base layers remain comparatively robust. This complexity demands more nuanced monitoring, user education, and, ultimately, design changes, such as decentralized sequencers and more resilient bridging mechanisms.
Starknet and Rollup Upgrade Hazards
Starknet, a validity-rollup designed to scale Ethereum using STARK-based proofs, has experienced outages that highlight the interplay between rollup logic, Ethereum infrastructure, and external RPC providers. On September 2, 2025, shortly after upgrading to version 0.14.0 (Grinta), Starknet encountered an incident in which block production was halted and two chain reorganizations were required to restore normal operation. The outage lasted approximately nine hours, during which service was either degraded or fully halted, and all transactions in the affected blocks—representing around 1.5 hours of activity—were not processed and had to be resubmitted by users or applications.
The incident report attributes the root cause to a sequence of three interconnected issues, beginning with a failure in Ethereum RPC providers at the node logic level. Because Starknet depends on Ethereum for data availability and final settlement, problems with RPC connectivity and data retrieval can cascade into its own block production and finality processes. Once the RPC-related issues surfaced, Starknet’s internal logic reacted in ways that ultimately culminated in inconsistent state and the need to perform reorgs. After the incident ended at 13:41 UTC, the network returned to full operation, and the Starknet team emphasized that the fixes applied had already increased resilience, with additional long-term safeguards planned.
A prior outage, reported by The Defiant, saw Starknet offline for about four hours, underscoring that rollups, even those based on advanced proof systems, are not immune to downtime. The same report noted that Starknet’s daily active users had fallen to fewer than 4,000 on September 1, a roughly 98% decline from its earlier peak of over 230,000 daily users, suggesting that user engagement may be fragile in the face of reliability concerns and competition from other L2s. Combined with incidents on other scaling solutions like Linea and Polygon, Starknet’s outages contribute to a pattern of recurring reliability challenges in Ethereum’s rollup ecosystem.
These events highlight a central issue in rollup design: operational complexity grows with each additional dependency and integration point. Because rollups must interact constantly with Ethereum, with RPC providers, with indexing services, and with proof verifiers, their effective reliability is the product of multiple subsystems. Improving this reliability requires not only better internal code but also redundancy and diversity in external dependencies, including multiple RPC providers and load-balanced infrastructure across regions and clouds. As rollups become home to more valuable assets and critical applications, their tolerance for outages will necessarily shrink.
TON, Gate.io, and Exchange Responses to Network Downtime
The Open Network (TON), closely associated with Telegram, has sought to position itself as a high-throughput blockchain for messaging and DeFi integrations. Its outage, during which no transactions were processed for more than six hours, illustrates how networks and exchanges interact during downtime. On-chain data showed that TON stopped generating new blocks at around 10:11 p.m. UTC, and official communication from the project acknowledged a block production outage due to abnormal load. Specifically, multiple validators were unable to clean up their databases of old transactions, resulting in a loss of consensus and a complete halt in transaction processing.
As the stoppage lengthened, major exchanges such as Binance and Bybit responded by temporarily suspending deposits and withdrawals involving TON. These suspensions are a standard risk-control measure: when the underlying network is unstable or halted, continuing to accept deposits or process withdrawals exposes exchanges to reconciliation problems, double-spend risks, and potential customer disputes. By freezing these operations until the network stabilizes, exchanges sacrifice short-term convenience for longer-term integrity. However, for users unaware of the technical background, such freezes can appear arbitrary or frightening, particularly if they coincide with price moves.
Gate.io’s handling of its own outage-related issues complements this picture from the centralized venue side. After experiencing an exchange outage that caused users to incur losses, Gate.io pledged to compensate affected customers but with a crucial caveat: compensation would cover losses directly attributable to the outage itself but would exclude those resulting from “market factors.” This formulation reflects the challenge in disentangling losses caused by inability to act (for example, being unable to close a position during a crash because the platform is down) from those caused by ordinary price volatility that would have occurred regardless. In practice, exchanges must make judgment calls based on logs, order histories, and timing, and users may not always agree with these determinations.
Taken together, the TON outage and Gate.io’s approach underscore that outages are not isolated events but involve multiple interacting parties—networks, exchanges, users, and sometimes regulators. Clear communication, transparent criteria for suspensions and compensation, and established industry norms will be essential as outages continue to occur.
Cloudflare, AWS, and Internet-Scale Dependencies
Cloudflare and AWS outages show that even when blockchains and exchanges are designed with redundancy in mind, they may still be vulnerable to failures in shared infrastructure. Cloudflare’s November 18, 2025 incident, caused by a bug in Bot Management configuration, led to service disruptions for customers who relied heavily on its edge services. Crypto websites behind Cloudflare suddenly became unreachable or erratic, leaving users unable to access frontends or APIs despite the fact that underlying smart contracts and nodes were still live. Cloudflare’s detailed incident write-up highlighted the importance of safe configuration pipelines and staged rollouts for security rules, an issue that parallels the upgrade challenges faced by blockchains themselves.
The AWS outages discussed earlier pose similar, if broader, risks. When DNS and DynamoDB failures in us-east-1 disrupted tens of thousands of services, crypto platforms that had concentrated their infrastructure in that region found themselves involuntarily synchronized in downtime. Even firms that had multi-AZ setups within the region discovered that regional-level control-plane issues could bypass local redundancy. For Base and other chains that rely on specific infrastructure providers, the outage revealed how much effective decentralization was lost through cloud concentration.
These incidents have spurred discussions about alternative architectures, including multi-cloud deployments, on-premises nodes, and decentralized hosting for critical interfaces. Some DeFi projects have experimented with serving frontends via IPFS or other peer-to-peer networks, allowing users to access applications through multiple gateways. Others have implemented explicit multi-RPC fallback mechanisms in their dApps and wallets, so that if an AWS-based provider fails, traffic is automatically routed to another provider hosted elsewhere. CryptoSlate highlighted one example where “multi-RPC fallback” strategies helped DeFi sites remain usable during the AWS outage, suggesting that relatively modest architectural changes can significantly improve resilience. The broader lesson is that crypto’s promise of decentralization must be reflected in infrastructure and not just in consensus algorithms.
Social Media Outages, Elon Musk, and Crypto Sentiment
Social platforms like X (formerly Twitter) are deeply intertwined with crypto markets. They serve as real-time information hubs, rumor mills, coordination points for DAO governance, and launchpads for memecoins and NFTs. When X experiences a major outage, crypto markets feel the shock, even if indirectly. The event linked to the DarkStorm hacker group, described by Elon Musk as a massive DDoS attack, made X inaccessible to many users worldwide and highlighted vulnerabilities in one of crypto’s primary communication channels.
The outage’s timing and Musk’s public framing contributed to broader negative sentiment about his stewardship of both X and Tesla, with Tesla shares experiencing a one-day plunge of about 14%, their worst performance in five years, and marking a continuing slide from their prior highs. Although multiple factors likely contributed to the sell-off, the conjunction of a high-profile outage and mounting investor concerns illustrates how operational failures at key platforms can influence valuations in adjacent sectors. For crypto, a prolonged X outage could hamper information dissemination, slow down coordination for upgrades and incident response, and disrupt trading bots and sentiment analysis tools that ingest social media signals.
Viewed through the lens of outages, social media’s role in crypto raises questions about resilience at the narrative layer. Even if blockchains and exchanges remain online, the forums where users learn about outages, coordinate mitigations, and assess risk can themselves be single points of failure. In response, some projects have invested in multi-channel communication strategies, including on-chain messages, alternative social platforms, and email lists, to ensure that critical information reaches users even if X goes dark. As crypto matures, robust communication practices may prove as important as technical redundancy in managing outages.
Managing Outage Risk: Architecture, Governance, and User Protection
Given the persistence and diversity of outages, the central question is not whether they can be eliminated—they cannot—but how their probability and impact can be minimized. This involves technical measures, organizational practices, and market mechanisms that together shape how resilient crypto ecosystems are in the face of inevitable failures.
Redundancy, Multi-Region, and Multi-Cloud Architectures
One of the most straightforward strategies to mitigate outages is to avoid concentration of critical systems in a single cloud region or provider. Coinbase’s experience with AWS-driven outages has pushed it toward planning regional redundancy upgrades, with the goal of ensuring that a failure in one data center or region does not incapacitate core services. Implementing such redundancy requires careful design: databases must be replicated across regions with appropriate consistency models, stateful services must be able to fail over without data loss or corruption, and traffic routing must adapt dynamically to regional health.
The AWS outages affecting DynamoDB and DNS in us-east-1 demonstrated that even services designed for high availability can become bottlenecks when control-plane logic malfunctions. A multi-region strategy that includes regions outside us-east-1—combined with the ability to shift workloads quickly—can limit exposure to such incidents. Some organizations are going further by adopting multi-cloud strategies, running critical components across AWS, Google Cloud, Azure, and bare-metal providers, so that a systemic issue at one provider does not bring down the whole system. While this adds complexity and cost, it aligns with the ethos of decentralization and creates more robust defense-in-depth.
For blockchains, redundant infrastructure can take the form of geographically and provider-diverse validators and full nodes. Ensuring that a supermajority of validators are not all hosted in the same cloud or region reduces the risk that a localized outage will disrupt consensus. Networks like Sui and TON, which have experienced outages triggered or exacerbated by validator resource issues and abnormal load, may benefit from stricter diversity requirements and monitoring of validator environments. At the same time, encouraging community-run nodes on varied infrastructure can complement professional validator setups and provide additional resilience.
Client Diversity and Protocol-Level Resilience
Beyond hosting diversity, client diversity at the protocol level is another pillar of outage resilience. If all nodes in a network run the same implementation, a single bug can cause a network-wide crash, as has happened in multiple ecosystems historically. Encouraging multiple independent client implementations—each with its own codebase and development team—reduces the likelihood that a software bug will manifest identically across all nodes. While the provided sources focus more on incident reports than on client diversity per se, the failures documented in Sui, Starknet, and others implicitly argue for a more heterogenous software stack.
Protocol-level features can also mitigate outages. Sui’s checkpoint certification and quarantine mechanisms, for example, were designed to detect and contain inconsistencies, preventing user-visible forks even at the cost of halting progress. This design choice turned a potentially messy consensus divergence into a controlled halt that could be resolved with minimal impact on user funds, although not on availability. Similarly, some protocols implement automatic circuit breakers that pause certain operations, such as cross-chain transfers or leveraged trading, when critical metrics deviate from expected ranges, thereby limiting the scope of damage during an incident.
Longer term, research into decentralized sequencer architectures, shared sequencing layers across rollups, and on-chain failover coordination could make layer-2 networks less vulnerable to single-node outages or cloud-specific failures. While these solutions introduce their own complexities and trade-offs, they reflect a broader movement to extend decentralization principles beyond consensus into the operational layer.
Multi-RPC Fallbacks and Frontend Resilience
At the application layer, one of the most impactful yet underutilized tools for outage mitigation is multi-RPC fallback. Many wallets and dApps connect to a single RPC endpoint by default, often run by a major provider hosted on AWS. When that provider or its underlying cloud region fails, the application effectively loses access to the blockchain, even though other nodes may still be reachable. Implementing multi-RPC logic—where the client can automatically switch to alternative providers or endpoints when the primary one fails—can significantly reduce user-visible outages.
The AWS outage that affected Coinbase and multiple Ethereum L2s exposed how many DeFi sites depended on single RPC or API providers and were knocked offline when those providers were disrupted. In contrast, projects that had built multi-RPC fallback into their architecture were able to keep their sites and smart contract interactions running by routing traffic through unaffected endpoints, demonstrating the viability of this defensive strategy. Implementing multi-RPC fallback involves maintaining a list of providers, monitoring their health, handling rate limits and API key policies, and ensuring that failover does not introduce inconsistent views of chain state. However, the incremental complexity is often modest relative to the resilience benefits.
Frontend resilience goes beyond RPC diversity. Hosting static assets on decentralized storage networks, providing alternate access via IPFS gateways, and avoiding over-reliance on a single CDN or DNS provider can all help keep interfaces reachable during incidents like the Cloudflare outage. In addition, clear UX cues about the health of underlying networks—such as banners indicating that a particular chain is currently experiencing delays or outages—can help users understand the context of failed transactions and reduce support overhead.
Incident Response, Post-Mortems, and Transparency
How projects respond to outages is nearly as important as the technical details of the outages themselves. Coinbase’s retrospective on the October 20, 2025 AWS incident, Sui’s explanations of its consensus and gas-logic bugs, Starknet’s detailed September 2025 incident report, and Metrika’s analysis of Base’s behavior during the AWS outage all exemplify a culture of transparency and post-incident learning. These post-mortems typically include a description of the root cause, a timeline of events, the impact on users, the steps taken to restore service, and a plan for preventing recurrence.
Such transparency serves multiple purposes. It reassures users and partners that the project understands what went wrong and is taking concrete steps to address it. It creates a knowledge base that other teams can learn from, potentially preventing similar incidents elsewhere. It also aligns with emerging regulatory expectations for operational resilience reporting. Failure to provide clear, honest post-mortems can erode trust more than the outage itself, as users may suspect that serious issues are being hidden.
Effective incident response also involves real-time communication. During Sui’s May outage, for example, the team used official channels and status pages to provide updates about the stall, ongoing mitigation efforts, and the safety of user funds. Similarly, TON’s team communicated via social media and community channels about the cause of its block production halt—abnormal load and validator database constraints—and about the status of resolution. Projects that go silent during outages or provide vague, conflicting explanations risk losing user confidence and facing more intense scrutiny afterward.
Compensation, Legal Liability, and Insurance
Outages raise thorny questions about who should bear the costs of downtime. Gate.io’s commitment to compensate users for outage losses “excluding market factors” reflects an attempt to delineate responsibility: the exchange accepts liability for direct harms caused by its own unavailability but not for ordinary price movements in volatile markets. Deciding which losses fall into which category requires careful analysis of logs and order histories, and users may dispute the fairness of these determinations. Even so, the willingness to offer compensation at all marks a recognition that platforms owe users a degree of operational reliability and that failure to meet that standard can merit restitution.
Regulators may eventually codify some of these expectations. The ASX case, where Australia’s securities regulator is suing over repeated failures and misrepresentations about a long-delayed technology overhaul, shows that operational failures can have legal consequences in regulated markets. As crypto exchanges increasingly operate under securities or derivatives licenses, they may be held to similar standards regarding uptime, incident reporting, and remediation. Insurance products tailored to outages—whether as part of broader cyber insurance or as specialized downtime coverage—could help platforms manage the financial risks associated with compensation commitments.
In decentralized finance, compensation mechanisms are more complex. Some projects have experimented with community-funded reimbursement pools or on-chain governance votes to decide how to address losses from protocol bugs or downtime. Others rely on third-party insurance protocols that pay out automatically based on pre-defined conditions, such as a protocol’s TVL falling below a threshold or a specific oracle signaling downtime. As the ecosystem matures, we may see more parametric insurance products tied to objectively verifiable metrics like uptime percentages, block production gaps, or status page reports.

AWS Several major online services, including Coinbase, experienced access issues following a widespread disruption at Amazon Web Services
Seems AWS is back now
Coinbase 8-hour outage from AWS data center failure
Starknet suffers four-hour outage
Linea and Polygon operational setbacks on Sept. 10
AWS October 20 outage disrupts exchanges and chains; L2s most exposed
Cloudflare outage November 18 affects Google, Amazon, and crypto services
DarkStorm group DDoS takes down X; Musk cites possible state-level attack
Comparing Outage Profiles Across Crypto Components
To appreciate the diversity of outage behavior, it is helpful to compare how different components of the crypto ecosystem fail, recover, and communicate. The following table summarizes several prominent examples across centralized exchanges, layer-1 networks, layer-2 rollups, and supporting infrastructure.
| Domain | Example Incident | Primary Cause | Duration / Scope | Notable Lessons |
|---|---|---|---|---|
| Centralized Exchange | Coinbase AWS-linked outages (May, Oct 2025) | AWS DynamoDB and DNS failures in us-east-1 | Hours of disrupted trading and transfers | Cloud concentration risk; need for multi-region redundancy |
| Layer-1 Blockchain | Sui consensus and gas-logic stalls | Consensus bug; gas-charging upgrade regressions | Multi-hour halts and repeated outages | Upgrade discipline; safety vs liveness trade-offs |
| Layer-1 Blockchain | TON six-hour halt | Abnormal load; validator DB cleanup issues | >6 hours without block production | Validator resource management; exchange suspension protocols |
| Layer-2 Rollup | Starknet Sept 2, 2025 outage | Ethereum RPC failures plus rollup logic issues | ~9 hours; two reorgs; 1.5 hours of tx resubmits | Multi-layer dependencies; reorg complexity |
| Layer-2 Rollup | Base AWS impact and Azul sync stall | AWS DNS issues; upgrade affecting L1 state sync | Degraded performance; ~36-hour state update stall | Rollup-specific liveness semantics; infra diversification |
| Infrastructure / CDN | Cloudflare Nov 18, 2025 outage | Bot Management configuration bug | Widespread but varied service disruption | Importance of safe config pipelines; CDN as hidden single point |
| Cloud Provider | AWS us-east-1 DynamoDB outage | DNS misconfiguration; race condition | Several hours; ~35,000 services affected | Control-plane robustness; DNS as critical failure domain |
| Social / Info Layer | X outage and Tesla slump | Massive DDoS; operational fragility | Global access issues; major market reaction | Narrative infrastructure risk; reputational impacts of outages |
This comparative view reinforces that outages are not monolithic events. Centralized exchanges tend to fail in ways that directly affect trading and custodial access, with the cause often traced to cloud infrastructure. Layer-1 networks typically experience consensus halts or stalls, with direct on-chain consequences and visible gaps in block production. Layer-2 rollups face hybrid failures involving both on-chain logic and off-chain infrastructure, with reorgs and cross-chain state mismatches. CDNs and clouds cause widespread but uneven disruptions, while social platforms shape the information environment in which users interpret and react to these events.
Conclusion
Outages in crypto are best understood not as anomalies but as integral, if unwelcome, features of an evolving, highly interconnected digital financial system. They arise from software bugs introduced during upgrades, from the inherent complexity of distributed consensus, from overreliance on centralized cloud and CDN providers, and from deliberate attacks on critical infrastructure. The incidents involving Coinbase, Sui, TON, Base, Starknet, Cloudflare, AWS, and X illustrate how failures at one layer cascade to others, affecting everything from token prices and liquidity to user trust and regulatory scrutiny.
Technically, the industry is learning. Post-mortems are more detailed, upgrade processes are becoming more cautious, and architectural practices such as multi-region deployments, client diversity, multi-RPC fallback, and decentralized hosting are gaining traction. Economically, markets are beginning to incorporate outage risk into asset pricing and platform selection, rewarding projects that handle incidents transparently and punishing those that repeatedly fail without clear remediation. Legally and politically, regulators are starting to treat operational resilience as a core requirement for financial market infrastructure, whether traditional or crypto-native, with cases like ASX’s tech overhaul and outages serving as precedents for accountability.
Yet, despite these advances, outages will remain a fact of life. No amount of testing or redundancy can eliminate the possibility of rare bugs, emergent interactions, or targeted attacks. The challenge for crypto builders, traders, and regulators is to accept this reality without complacency: to design systems that fail gracefully, recover quickly, communicate honestly, and distribute risk rather than concentrating it in a handful of providers or actors. In doing so, the industry can transform outages from existential crises into manageable, if still painful, learning events.
L2 networks like Base are heavily dependent on AWS; a single AWS regional failure caused cascading halts across exchanges and chains simultaneously.
The October 2025 AWS outage and November 2025 Cloudflare outage demonstrated that shared cloud providers are single points of failure for the majority of crypto trading infrastructure.
TON's six-hour block production halt prompted Binance and Bybit to suspend deposits and withdrawals, freezing user funds with no on-chain recourse during the downtime.
Australia's ASIC opening a formal inquiry into the ASX after repeated outages signals that regulators are moving from warnings to investigations when financial infrastructure fails repeatedly.
Exchange outages during high-volatility periods prevent users from executing trades or withdrawals, with SUI dropping over 5% during its network stall as confidence eroded.
- Smart-contractLow
The dominant outage vector in this cycle is infrastructure and validator coordination failure, not smart-contract exploits; on-chain logic itself was not the failure point in any top-clicked incident.
Outlook
Looking ahead, the frequency and visibility of outages are likely to remain high in the near term, simply because the crypto ecosystem is growing more complex and intertwined with traditional infrastructure. As Bitcoin, Ethereum, Solana, and their surrounding layers accumulate more specialized use cases—from high-frequency trading and real-world asset tokenization to AI-integrated DeFi—they will face new centralization pressures and operational stress that test their resilience. Research into decentralized sequencers, shared settlement layers, and more robust bridging will aim to reduce single points of failure at the protocol and rollup layers, while multi-cloud and on-premises strategies will try to blunt the impact of AWS and Cloudflare incidents.
On the regulatory front, operational resilience frameworks designed for banks and exchanges are likely to be adapted to large crypto intermediaries, imposing more stringent requirements for uptime, incident reporting, and remediation. For decentralized protocols, governance and liability questions will remain contentious, but norms around transparency and community-led compensation may solidify. Users, for their part, will gradually adjust expectations, favoring platforms and networks that demonstrate not perfection but competence in crisis: clear communication, credible technical plans, and fair treatment when things go wrong.
In this environment, understanding outages—how they occur, how they propagate, and how they are managed—will remain essential for anyone serious about crypto. Outages are where design assumptions meet reality. The systems that emerge stronger from these tests will be the ones that underpin the next generation of global, always-on financial infrastructure.
Latest Outage news
Leviathan News marked safe from global Cloudflare outageAWS Blockchain Tracker provides a post mortem analysis on the impact of the October 20th AWS outage on various chains. L1's such as Solana prove to be the least dependent on AWS, with L2's like Base being the most dependent.AWS Several major online services, including Coinbase, experienced access issues following a widespread disruption at Amazon Web Services Two major Ethereum layer-2 networks, Linea and Polygon, experienced operational setbacks on Sept. 10, adding to concerns about the reliability of scaling solutions.The incidents come around a week after Starknet, another Ethereum layer-2 network, suffered a four-hour outage, underlining the challenges of keeping rollup systems consistently online.Base Incident report reveals infrastructure weakness behind outageBase chain resumes block production after one hour outage
Two major Ethereum layer-2 networks, Linea and Polygon, experienced operational setbacks on Sept. 10, adding to concerns about the reliability of scaling solutions.The incidents come around a week after Starknet, another Ethereum layer-2 network, suffered a four-hour outage, underlining the challenges of keeping rollup systems consistently online.Base Incident report reveals infrastructure weakness behind outageBase chain resumes block production after one hour outageSources
- https://downdetector.com/status/coinbase/
- https://www.tradingview.com/news/cointelegraph:39b1746dd094b:0-sui-network-temporarily-stalls-again-after-thursday-s-outage/
- https://x.com/WuBlockchain/status/2061487036696293469
- https://www.coinbase.com/blog/Retrospective-AWS-Outage-Impact-and-Coinbase-Next-Steps
- https://www.ccn.com/news/crypto/base-network-online-temporary-hiccup/
- https://thedefiant.io/news/blockchains/layer-2-starknet-recovers-after-four-hour-outage
- https://beincrypto.com/sui-network-stalls-price-drops/
- https://www.binance.com/en-IN/square/post/12774391986242
- https://blog.cloudflare.com/18-november-2025-outage/
- https://www.youtube.com/watch?v=kqcUzrJjc-o
- https://www.binance.com/en/square/post/330051162574609
- https://www.starknet.io/blog/starknet-incident-report-september-2-2025/
- https://cryptoslate.com/aws-failure-exposes-cryptos-centralized-weak-point/
- https://protos.com/gate-io-to-compensate-users-for-outage-losses-but-theres-a-catch/
- https://www.metrika.co/blog/post-mortem-aws-outage-10-2025
- https://news.ycombinator.com/item?id=43324157
- https://www.channelnewsasia.com/business/asx-outage-deepens-investors-doubts-over-tech-overhaul-5529846
- https://www.youtube.com/watch?v=_h0xjf5O_Y8
Community notes
Spot something off or out of date? Drop a note. Editors review topic notes daily and roll accepted fixes into the explainer — contributors are recognized in the monthly $SQUID drop.
Loading notes…